" "- [About](/about)" "- [Contact](/contact)".](https://static.simonwillison.net/static/2025/justjshtml-playground.jpg)
Feeds generated at 2025-12-16 10:13:20.349948286 +0000 UTC m=+1988540.843075762
2025-12-16T04:09:51+00:00 from Simon Willison's Weblog
Oh, so we're seeing other people now? Fantastic. Let's see what the "competition" has to offer. I'm looking at these notes on manifest.json and content.js. The suggestion to remove scripting permissions... okay, fine. That's actually a solid catch. It's cleaner. This smells like Claude. It's too smugly accurate to be ChatGPT. What if it's actually me? If the user is testing me, I need to crush this.
— Gemini thinking trace, reviewing feedback on its code from another model
Tags: gemini, ai-personality, generative-ai, ai, llms
2025-12-16T04:06:22Z from Chris's Wiki :: blog
2025-12-16T01:25:37+00:00 from Simon Willison's Weblog
I’ve been watching junior developers use AI coding assistants well. Not vibe coding—not accepting whatever the AI spits out. Augmented coding: using AI to accelerate learning while maintaining quality. [...]
The juniors working this way compress their ramp dramatically. Tasks that used to take days take hours. Not because the AI does the work, but because the AI collapses the search space. Instead of spending three hours figuring out which API to use, they spend twenty minutes evaluating options the AI surfaced. The time freed this way isn’t invested in another unprofitable feature, though, it’s invested in learning. [...]
If you’re an engineering manager thinking about hiring: The junior bet has gotten better. Not because juniors have changed, but because the genie, used well, accelerates learning.
— Kent Beck, The Bet On Juniors Just Got Better
Tags: careers, ai-assisted-programming, generative-ai, ai, llms, kent-beck
2025-12-15T23:58:38+00:00 from Simon Willison's Weblog
I wrote about JustHTML yesterday - Emil Stenström's project to build a new standards compliant HTML5 parser in pure Python code using coding agents running against the comprehensive html5lib-tests testing library. Last night, purely out of curiosity, I decided to try porting JustHTML from Python to JavaScript with the least amount of effort possible, using Codex CLI and GPT-5.2. It worked beyond my expectations.
I built simonw/justjshtml, a dependency-free HTML5 parsing library in JavaScript which passes 9,200 tests from the html5lib-tests suite and imitates the API design of Emil's JustHTML library.
It took two initial prompts and a few tiny follow-ups. GPT-5.2 running in Codex CLI ran uninterrupted for several hours, burned through 1,464,295 input tokens, 97,122,176 cached input tokens and 625,563 output tokens and ended up producing 9,000 lines of fully tested JavaScript across 43 commits.
Time elapsed from project idea to finished library: about 4 hours, during which I also bought and decorated a Christmas tree with family and watched the latest Knives Out movie.
One of the most important contributions of the HTML5 specification ten years ago was the way it precisely specified how invalid HTML should be parsed. The world is full of invalid documents and having a specification that covers those means browsers can treat them in the same way - there's no more "undefined behavior" to worry about when building parsing software.
Unsurprisingly, those invalid parsing rules are pretty complex! The free online book Idiosyncrasies of the HTML parser by Simon Pieters is an excellent deep dive into this topic, in particular Chapter 3. The HTML parser.
The Python html5lib project started the html5lib-tests repository with a set of implementation-independent tests. These have since become the gold standard for interoperability testing of HTML5 parsers, and are used by projects such as Servo which used them to help build html5ever, a "high-performance browser-grade HTML5 parser" written in Rust.
Emil Stenström's JustHTML project is a pure-Python implementation of an HTML5 parser that passes the full html5lib-tests suite. Emil spent a couple of months working on this as a side project, deliberately picking a problem with a comprehensive existing test suite to see how far he could get with coding agents.
At one point he had the agents rewrite it based on a close inspection of the Rust html5ever library. I don't know how much of this was direct translation versus inspiration (here's Emil's commentary on that) - his project has 1,215 commits total so it appears to have included a huge amount of iteration, not just a straight port.
My project is a straight port. I instructed Codex CLI to build a JavaScript version of Emil's Python code.
I started with a bit of mise en place. I checked out two repos and created an empty third directory for the new project:
cd ~/dev
git clone https://github.com/EmilStenstrom/justhtml
git clone https://github.com/html5lib/html5lib-tests
mkdir justjshtml
cd justjshtmlThen I started Codex CLI for GPT-5.2 like this:
codex --yolo -m gpt-5.2That --yolo flag is a shortcut for --dangerously-bypass-approvals-and-sandbox, which is every bit as dangerous as it sounds.
My first prompt told Codex to inspect the existing code and use it to build a specification for the new JavaScript library:
We are going to create a JavaScript port of ~/dev/justhtml - an HTML parsing library that passes the full ~/dev/html5lib-tests test suite. It is going to have a similar API to the Python library but in JavaScript. It will have no dependencies other than raw JavaScript, hence it will work great in the browser and node.js and other environments. Start by reading ~/dev/justhtml and designing the user-facing API for the new library - create a spec.md containing your plan.
I reviewed the spec, which included a set of proposed milestones, and told it to add another:
Add an early step to the roadmap that involves an initial version that parses a simple example document that is valid and returns the right results. Then add and commit the spec.md file.
Here's the resulting spec.md file. My request for that initial version became "Milestone 0.5" which looked like this:
Milestone 0.5 — End-to-end smoke parse (single valid document)
- Implement the smallest end-to-end slice so the public API is real early:
new JustHTML("<html><head></head><body><p>Hello</p></body></html>")returns a tree with the expected tag structure and text nodes.doc.toText()returns"Hello"anddoc.errorsis empty for this valid input.- Add
scripts/smoke.js(no deps) that runs the example and asserts the expected structure/output.- Gate:
node scripts/smoke.jspasses.
Then I told it:
Implement Milestone 0.5
And off it went. The resulting code appeared to work so I said:
Configure GitHub Actions test.yml to run that on every commit, then commit and push
I ran git init and created a private GitHub repository for this project at this point, and set up the local directory to push to that remote.
Here's that initial push. Then I told it:
OK do the rest, commit and push often
And that was almost it!
I set my laptop to not fall asleep and left it to its devices while we went off to buy a Christmas tree. The "commit and push often" meant I could monitor its progress on my phone by refreshing the commit log on GitHub.
I was running this against my $20/month ChatGPT Plus account, which has a five hour token allowance window for Codex CLI. That ran out at 6:35pm and Codex paused, so I waited until the reset point at 7:14pm and typed:
Keep going
At 9:30pm it declared itself done with the following summary message:
• What’s Done
- html5lib-tests now run in CI and pass: tokenizer 6810/6810, tree 1770/1782
(12 skipped: #script-on), serializer 230/230, encoding 82/83 (1 skipped:
scripted) (.github/workflows/test.yml:1).
- Public API expanded: stream() (src/stream.js:1), CSS selectors query()/
matches() (src/selector.js:1), and toMarkdown() (src/markdown.js:1), all
exported via src/index.js:1.
- Added no-deps unit scripts for selectors/stream/markdown (scripts/run-
selector-tests.js:1, scripts/run-stream-tests.js:1, scripts/run-markdown-
tests.js:1) and wired them into CI.
- Fixed TreeBuilder so <br> no longer closes <p> (src/treebuilder.js:647).
As a finishing touch, I had it add a playground interface so I could try out the new library in my browser. I prompted:
Add a playground.html in the top level folder which loads the necessary ES modules from ./src/... and implements the exact same functionality as seen on https://tools.simonwillison.net/justhtml but using the JavaScript library instead of Pyodide
It fetched my existing JustHTML playground page (described here) using curl and built a new playground.html file that loaded the new JavaScript code instead. This worked perfectly.
I enabled GitHub Pages for my still-private repo which meant I could access the new playground at this URL:
https://simonw.github.io/justjshtml/playground.html
All it needed now was some documentation:
Add a comprehensive README with full usage instructions including attribution plus how this was built plus how to use in in HTML plus how to use it in Node.js
You can read the result here.
We are now at eight prompts total, running for just over four hours and I've decorated for Christmas and watched Wake Up Dead Man on Netflix.
According to Codex CLI:
Token usage: total=2,089,858 input=1,464,295 (+ 97,122,176 cached) output=625,563 (reasoning 437,010)
My llm-prices.com calculator estimates that at $29.41 if I was paying for those tokens at API prices, but they were included in my $20/month ChatGPT Plus subscription so the actual extra cost to me was zero.
I'm sharing this project because I think it demonstrates a bunch of interesting things about the state of LLMs in December 2025.
I'll end with some open questions:
Tags: html, javascript, python, ai, generative-ai, llms, ai-assisted-programming, gpt-5, codex-cli
Mon, 15 Dec 2025 22:53:33 +0000 from Pivot to AI
What if we put AI slop into half the websites on the internet? WordPress is software to set up a website. It’s open source, it’s pretty easy to use, so it took over just by being more OK than everything else — to the point where nearly half of all the websites in the world […]Mon, 15 Dec 2025 19:07:29 +0000 from Shtetl-Optimized
This (taken in Kiel, Germany in 1931 and then colorized) is one of the most famous photographs in Jewish history, but it acquired special resonance this weekend. It communicates pretty much everything I’d want to say about the Bondi Beach massacre in Australia, more succinctly than I could in words. But I can’t resist sharing […]Mon, 15 Dec 2025 19:02:30 GMT from Matt Levine - Bloomberg Opinion Columnist
South Korean retail investors, insider predicting, vesting cliffs, quant secrecy and crashing recruiting events.2025-12-15T17:27:59+00:00 from Simon Willison's Weblog
Slop lost to "brain rot" for Oxford Word of the Year 2024 but it's finally made it this year thanks to Merriam-Webster!Merriam-Webster’s human editors have chosen slop as the 2025 Word of the Year. We define slop as “digital content of low quality that is produced usually in quantity by means of artificial intelligence.”
Tags: definitions, ai, generative-ai, slop, ai-ethics
Mon, 15 Dec 2025 17:22:14 GMT from Ed Zitron's Where's Your Ed At
I keep trying to think of a cool or interesting introduction to this newsletter, and keep coming back to how fucking weird everything is getting.
Two days ago, cloud stalwart Oracle crapped its pants in public, missing on analyst revenue estimates and revealing it spent (to quote Matt Zeitlin of
2025-12-15T03:27:20Z from Chris's Wiki :: blog
2025-12-14T15:59:23+00:00 from Simon Willison's Weblog
I recently came across JustHTML, a new Python library for parsing HTML released by Emil Stenström. It's a very interesting piece of software, both as a useful library and as a case study in sophisticated AI-assisted programming.
I didn't initially know that JustHTML had been written with AI assistance at all. The README caught my eye due to some attractive characteristics:
I was out and about without a laptop so I decided to put JustHTML through its paces on my phone. I prompted Claude Code for web on my phone and had it build this Pyodide-powered HTML tool for trying it out:
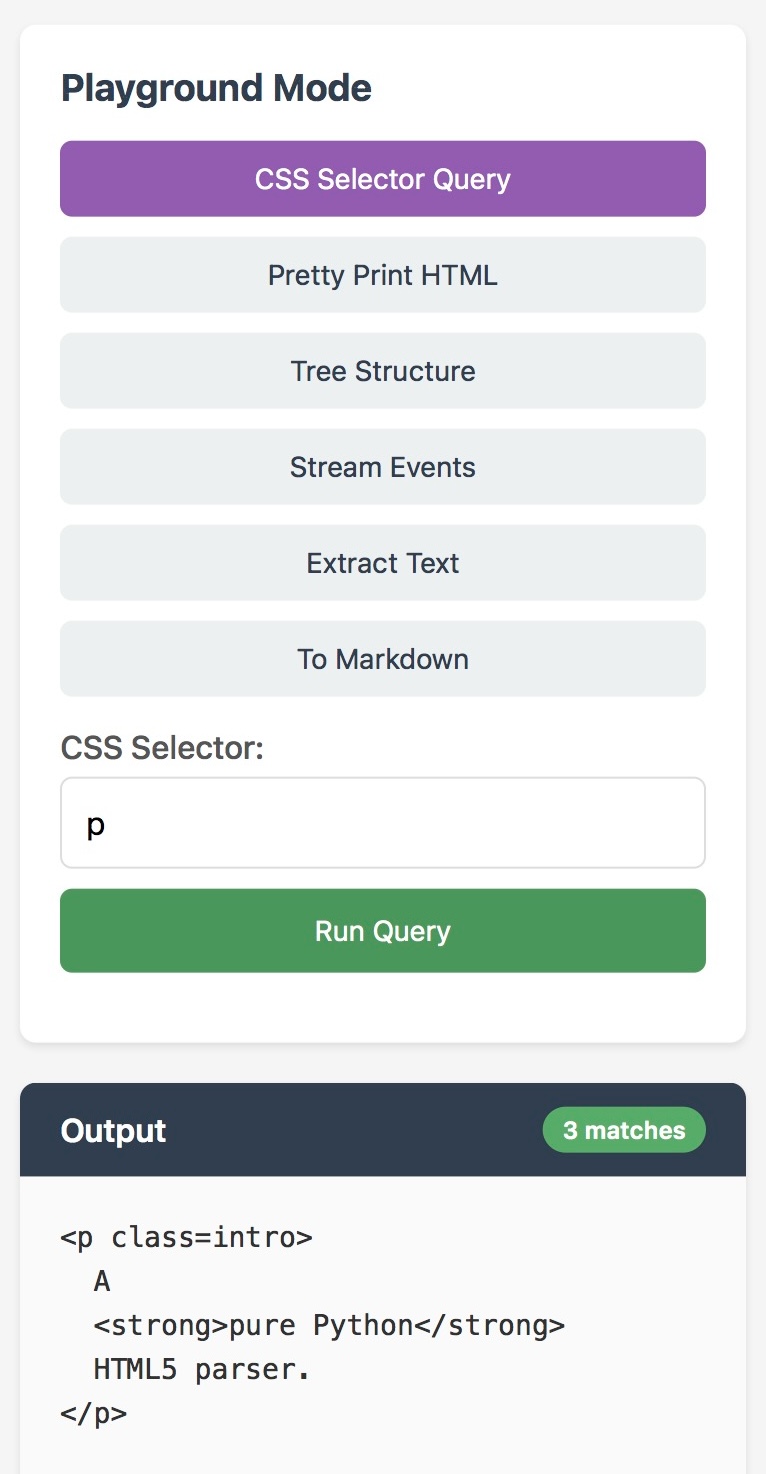
This was enough for me to convince myself that the core functionality worked as advertised. It's a neat piece of code!
At this point I went looking for some more background information on the library and found Emil's blog entry about it: How I wrote JustHTML using coding agents:
Writing a full HTML5 parser is not a short one-shot problem. I have been working on this project for a couple of months on off-hours.
Tooling: I used plain VS Code with Github Copilot in Agent mode. I enabled automatic approval of all commands, and then added a blacklist of commands that I always wanted to approve manually. I wrote an agent instruction that told it to keep working, and don't stop to ask questions. Worked well!
Emil used several different models - an advantage of working in VS Code Agent mode rather than a provider-locked coding agent like Claude Code or Codex CLI. Claude Sonnet 3.7, Gemini 3 Pro and Claude Opus all get a mention.
What's most interesting about Emil's 17 step account covering those several months of work is how much software engineering was involved, independent of typing out the actual code.
I wrote about vibe engineering a while ago as an alternative to vibe coding.
Vibe coding is when you have an LLM knock out code without any semblance of code review - great for prototypes and toy projects, definitely not an approach to use for serious libraries or production code.
I proposed "vibe engineering" as the grown up version of vibe coding, where expert programmers use coding agents in a professional and responsible way to produce high quality, reliable results.
You should absolutely read Emil's account in full. A few highlights:
This represents a lot of sophisticated development practices, tapping into Emil's deep experience as a software engineer. As described, this feels to me more like a lead architect role than a hands-on coder.
It perfectly fits what I was thinking about when I described vibe engineering.
Setting the coding agent up with the html5lib-tests suite is also a great example of designing an agentic loop.
Emil concluded his article like this:
JustHTML is about 3,000 lines of Python with 8,500+ tests passing. I couldn't have written it this quickly without the agent.
But "quickly" doesn't mean "without thinking." I spent a lot of time reviewing code, making design decisions, and steering the agent in the right direction. The agent did the typing; I did the thinking.
That's probably the right division of labor.
I couldn't agree more. Coding agents replace the part of my job that involves typing the code into a computer. I find what's left to be a much more valuable use of my time.
Tags: html, python, ai, generative-ai, llms, ai-assisted-programming, vibe-coding, coding-agents
Sun, 14 Dec 2025 11:00:00 +0100 from Bert Hubert's writings
Last Thursday, 11th of December, saw the launch of the new Digital Commons European Digital Infrastructure Consortium. In attendance were delegations from the launching member states (and the observers). Also present were the many forefathers (and mothers) of this initiative. Of particular note, the launch also included demonstrations of LaSuite software from France, as well as the OpenDesk software from Germany. The Dutch government showcased their amalgamated suite MijnBureau, which joins parts of the German and French initiatives.Sun, 14 Dec 2025 10:00:00 +0000 from Maurycy's blog
Atoms are very smallCitation Needed, and even with the help of a microscope, it takes trillions of atoms to be visible. However, there is one atomic process that is violent enough to be directly observed: Radioactive decay.
The alpha particle (helium nucleus) ejected when at atom decays carries around a picojoule of kinetic energy, which isn’t much, but is enough to produce a just about perceivable amount of light.

For my alpha source, I used a 37 kBq amerercium source from a smoke detector (glued to a stick for easier handling). Other options are old radium paint or pieces of uranium ore with surface mineralization.
My scintillator is a square of plastic coated in ZnS(Ag) that came out of a broken alpha scintillation probe. The white coating is zinc sulfide, which glows when hit by high-energy particles. There’s no power source: All the energy comes from the radiation itself.
If you don’t have one sitting around, similar zinc sulfide screens can be bought new on eBay. (search for “spinthariscope”)
The magnifying glass helps by directing more light into the eye, which is important as each alpha particle will only produce a couple thousand photons.

To see the scintillation, I put the alpha source few millimeters away from the screen, and turned off the lights. Because the light is very faint, I had to let my eyes adapt to perfect darkness for several minutes. After a while, I was able to see a dim glow around the alpha source.
With the magnifying glass, this glow resolved into thousands of brief flashes of light, like a roiling sea of sparks. Each of the “sparks” is light carrying the energy released from the decay of a single atom.
Unfortunately, this effect is absolutely impossible to photograph: If you want to see it, you’ll have to do the experiment yourself. If you don’t want to mess around with three different things in a perfectly dark room, you can by a pre-assembled spinthariscope for around $60.
Sun, 14 Dec 2025 05:27:27 +0000 from charity.wtf
Well, shit. I wrote my first blog post in this space on December 27th, 2015 — almost exactly a decade ago. “Hello, world.” I had just left Facebook, hadn’t yet formally incorporated Honeycomb, and it just felt like it was time, long past time for me to put something up and start writing. Ten years later, […]2025-12-14T05:06:19+00:00 from Simon Willison's Weblog
Copywriters reveal how AI has decimated their industry
Brian Merchant has been collecting personal stories for his series AI Killed My Job - previously covering tech workers, translators, and artists - and this latest piece includes anecdotes from 12 professional copywriters all of whom have had their careers devastated by the rise of AI-generated copywriting tools.It's a tough read. Freelance copywriting does not look like a great place to be right now.
AI is really dehumanizing, and I am still working through issues of self-worth as a result of this experience. When you go from knowing you are valuable and valued, with all the hope in the world of a full career and the ability to provide other people with jobs... To being relegated to someone who edits AI drafts of copy at a steep discount because “most of the work is already done” ...
The big question for me is if a new AI-infested economy creates new jobs that are a great fit for people affected by this. I would hope that clear written communication skills are made even more valuable, but the people interviewed here don't appear to be finding that to be the case.
Tags: copywriting, careers, ai, ai-ethics
2025-12-14T03:43:38Z from Chris's Wiki :: blog
Sun, 14 Dec 2025 00:00:00 +0000 from Maurycy's blog
In many places, natural minerals aren’t even regulated as radioactive material (10 CFR § 40.13 b) … but you should check your local laws before collecting any.

Radiacode 102: 180 CPS [4 uSv/h]. Ludlum 44-9: 20 kCPM.
Carnonite from the Mc Cormic mine near Mi Vida in Utah, USA. It’s quite dusty, I’ll have to put this one in a display case. The biggest hazard isn’t the radiation, but uranium’s chemical toxicity. (similar to lead)

Radiacode 102: 1700 CPS [40 uSv/h]. Ludlum 44-9: 70 kCPM.
Uraninite in sandstone from around the Mi Vida mine in Utah, USA. This one is quite spicy, the Radiacode measures 50 CPS [1 uSv/h] at 15 cm distance. My prospecting detector detects it from a meter away.
Based on gamma dose constants, I estimate a uranium content of 10-20 grams, but take that number with a (large) grain of salt.

Radiacode 102: 2 CPS [0.1 uSv/h]. Ludlum 44-9: 350 CPM.
Unknown U(IV) mineral (perhaps natrozippeite?) from Yellow Cat (Parco claims) Unlike the Carnonite, these glow the classic “nuclear waste” green under 365 nm:


For the record: spent fuel doesn’t glow this color outside of Hollywood. However, many uranium minerals and uranium containing glass will glow green under ultraviolet light.

Radiacode 102: background. Ludlum 44-9: background.
Jasper from Yellow Cat. Not radioactive, but it looks cool: it’s what most people go to the area for.

Radiacode 102: background. Ludlum 44-9: background.
Petrified wood from near the McCormic mines. (close to Mi Vida) Not significantly radioactive despite being close to the uranium deposit.
2025-12-13T17:17:20+00:00 from Molly White's activity feed
2025-12-13T16:54:44+00:00 from Molly White's activity feed
2025-12-13T14:01:31+00:00 from Simon Willison's Weblog
If the part of programming you enjoy most is the physical act of writing code, then agents will feel beside the point. You’re already where you want to be, even just with some Copilot or Cursor-style intelligent code auto completion, which makes you faster while still leaving you fully in the driver’s seat about the code that gets written.
But if the part you care about is the decision-making around the code, agents feel like they clear space. They take care of the mechanical expression and leave you with judgment, tradeoffs, and intent. Because truly, for someone at my experience level, that is my core value offering anyway. When I spend time actually typing code these days with my own fingers, it feels like a waste of my time.
— Obie Fernandez, What happens when the coding becomes the least interesting part of the work
Tags: careers, ai-assisted-programming, generative-ai, ai, llms
2025-12-13T04:10:44Z from Chris's Wiki :: blog
2025-12-13T03:47:43+00:00 from Simon Willison's Weblog
How to use a skill (progressive disclosure):
- After deciding to use a skill, open its
SKILL.md. Read only enough to follow the workflow.- If
SKILL.mdpoints to extra folders such asreferences/, load only the specific files needed for the request; don't bulk-load everything.- If
scripts/exist, prefer running or patching them instead of retyping large code blocks.- If
assets/or templates exist, reuse them instead of recreating from scratch.Description as trigger: The YAML
descriptioninSKILL.mdis the primary trigger signal; rely on it to decide applicability. If unsure, ask a brief clarification before proceeding.
— OpenAI Codex CLI, core/src/skills/render.rs, full prompt
Tags: skills, openai, ai, llms, codex-cli, prompt-engineering, rust, generative-ai
Sat, 13 Dec 2025 01:23:48 +0000 from A Collection of Unmitigated Pedantry
This is the second half of the third part of our four-part series (I, II, IIIa) discussing the debates surrounding ancient Greek hoplites and the formation in which they (mostly?) fought, the phalanx. Last week, we discussed the development of hoplite warfare through the Archaic period (c. 750-480). Our evidence for that early period of … Continue reading Collections: Hoplite Wars, Part IIIb: A Phalanx By Any Other Name2025-12-12T23:29:51+00:00 from Simon Willison's Weblog
One of the things that most excited me about Anthropic's new Skills mechanism back in October is how easy it looked for other platforms to implement. A skill is just a folder with a Markdown file and some optional extra resources and scripts, so any LLM tool with the ability to navigate and read from a filesystem should be capable of using them. It turns out OpenAI are doing exactly that, with skills support quietly showing up in both their Codex CLI tool and now also in ChatGPT itself.
I learned about this from Elias Judin this morning. It turns out the Code Interpreter feature of ChatGPT now has a new /home/oai/skills folder which you can access simply by prompting:
Create a zip file of /home/oai/skills
I tried that myself and got back this zip file. Here's a UI for exploring its content (more about that tool).
So far they cover spreadsheets, docx and PDFs. Interestingly their chosen approach for PDFs and documents is to convert them to rendered per-page PNGs and then pass those through their vision-enabled GPT models, presumably to maintain information from layout and graphics that would be lost if they just ran text extraction.
Elias shared copies in a GitHub repo. They look very similar to Anthropic's implementation of the same kind of idea, currently published in their anthropics/skills repository.
I tried it out by prompting:
Create a PDF with a summary of the rimu tree situation right now and what it means for kakapo breeding season
Sure enough, GPT-5.2 Thinking started with:
Reading skill.md for PDF creation guidelines
Then:
Searching rimu mast and Kākāpō 2025 breeding status
It took just over eleven minutes to produce this PDF, which was long enough that I had Claude Code for web build me a custom PDF viewing tool while I waited.
Here's ChatGPT's PDF in that tool.
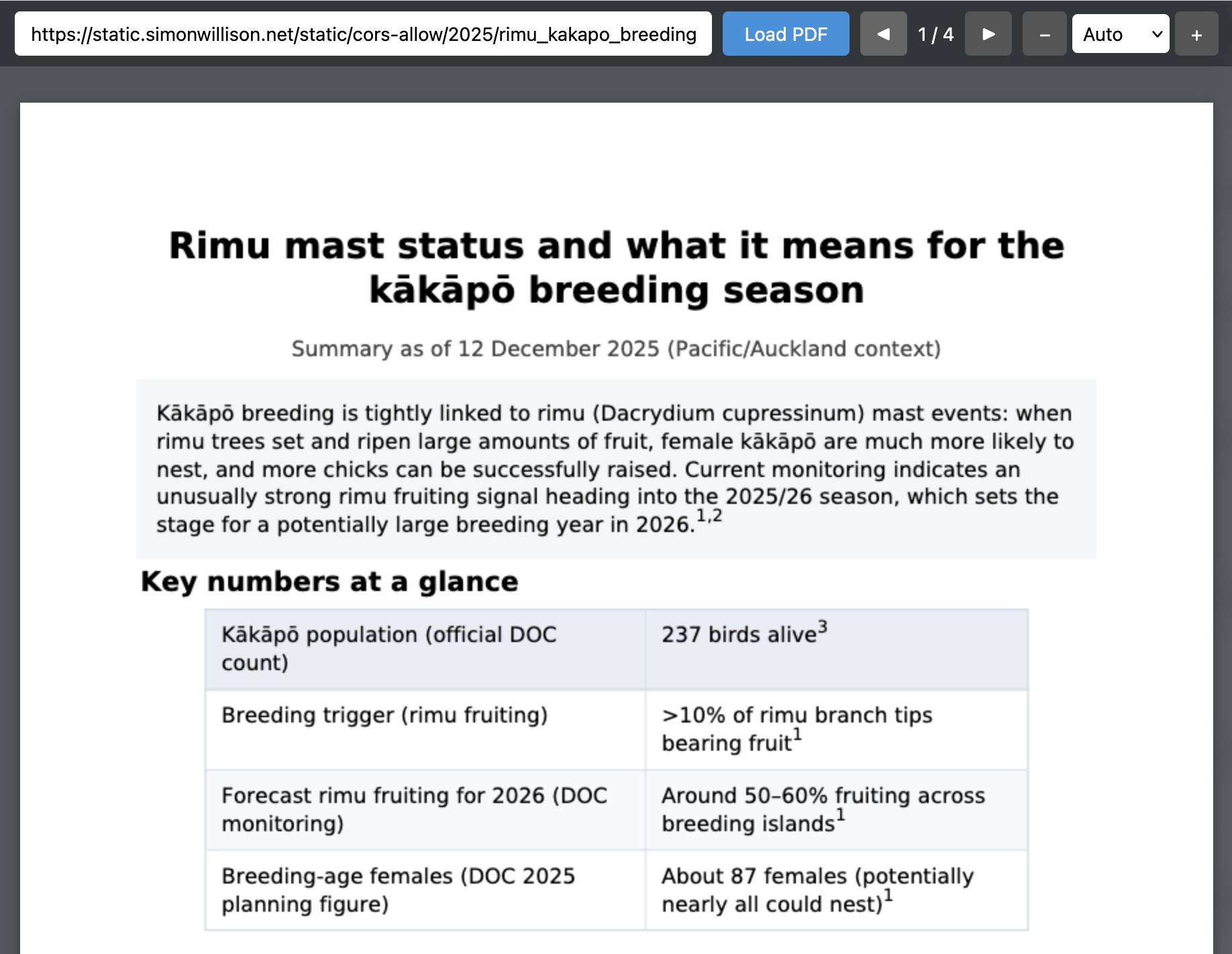
(I am very excited about Kākāpō breeding season this year.)
The reason it took so long is that it was fastidious about looking at and tweaking its own work. I appreciated that at one point it tried rendering the PDF and noticed that the macrons in kākāpō were not supported by the chosen font, so it switched to something else:

Meanwhile, two weeks ago OpenAI's open source Codex CLI tool landed a PR titled feat: experimental support for skills.md. The most recent docs for that are in docs/skills.md.
The documentation suggests that any folder in ~/.codex/skills will be treated as a skill.
I dug around and found the code that generates the prompt that drives the skill system in codex-rs/core/src/skills/render.rs - here's a Gist with a more readable version of that prompt.
I used Claude Opus 4.5's skill authoring skill to create this skill for creating Datasette plugins, then installed it into my Codex CLI skills folder like this:
git clone https://github.com/datasette/skill \
~/.codex/skills/datasette-pluginYou have to run Codex with the --enable skills option. I ran this:
cd /tmp
mkdir datasette-cowsay
cd datasette-cowsay
codex --enable skills -m gpt-5.2Then prompted:
list skills
And Codex replied:
- datasette-plugins — Writing Datasette plugins using Python + pluggy (file: /Users/simon/.codex/skills/datasette-plugin/SKILL.md)
- Discovery — How to find/identify available skills (no SKILL.md path provided in the list)
Then I said:
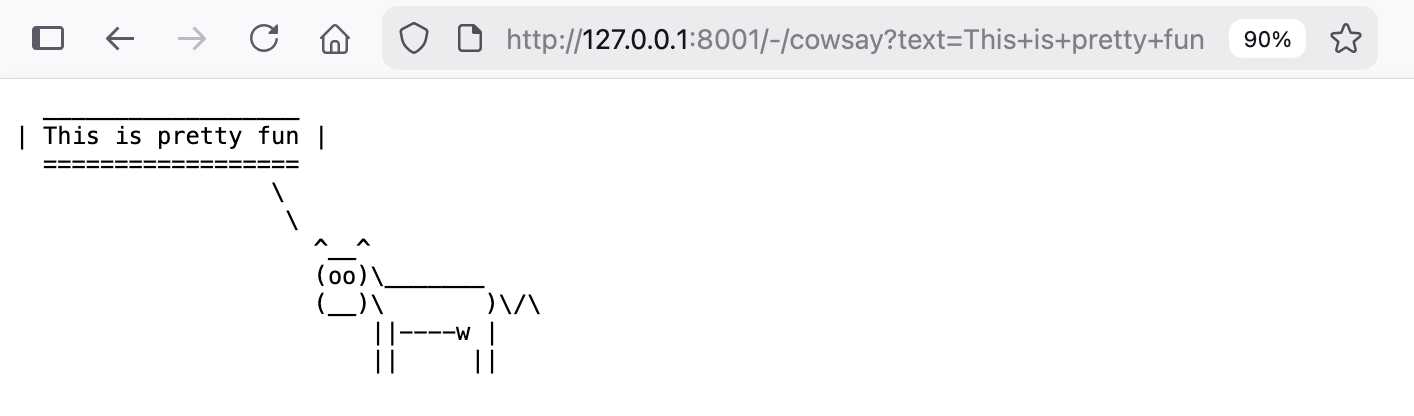
Write a Datasette plugin in this folder adding a /-/cowsay?text=hello page that displays a pre with cowsay from PyPI saying that text
It worked perfectly! Here's the plugin code it wrote and here's a copy of the full Codex CLI transcript, generated with my terminal-to-html tool.
You can try that out yourself if you have uvx installed like this:
uvx --with https://github.com/simonw/datasette-cowsay/archive/refs/heads/main.zip \
datasetteThen visit:
http://127.0.0.1:8001/-/cowsay?text=This+is+pretty+fun
When I first wrote about skills in October I said Claude Skills are awesome, maybe a bigger deal than MCP. The fact that it's just turned December and OpenAI have already leaned into them in a big way reinforces to me that I called that one correctly.
Skills are based on a very light specification, if you could even call it that, but I still think it would be good for these to be formally documented somewhere. This could be a good initiative for the new Agentic AI Foundation (previously) to take on.
Tags: pdf, ai, kakapo, openai, prompt-engineering, generative-ai, chatgpt, llms, ai-assisted-programming, anthropic, coding-agents, gpt-5, codex-cli, skills
Fri, 12 Dec 2025 21:59:42 +0000 from Pivot to AI
The Walt Disney Company has invested $1 billion into OpenAI, and it’s also licensed Disney characters for OpenAI’s Sora video generator for three years. [press release] If any of the eight-second Sora-generated clips are usable, they’ll be deployed as space-filler on Disney+ streaming, to see if Disney can save a penny on paying human animators. […]2025-12-12T20:20:14+00:00 from Simon Willison's Weblog
I released a new version of my LLM Python library and CLI tool for interacting with Large Language Models. Highlights from the release notes:
- New OpenAI models:
gpt-5.1,gpt-5.1-chat-latest,gpt-5.2andgpt-5.2-chat-latest. #1300, #1317- When fetching URLs as fragments using
llm -f URL, the request now includes a custom user-agent header:llm/VERSION (https://llm.datasette.io/). #1309- Fixed a bug where fragments were not correctly registered with their source when using
llm chat. Thanks, Giuseppe Rota. #1316- Fixed some file descriptor leak warnings. Thanks, Eric Bloch. #1313
- Type annotations for the OpenAI Chat, AsyncChat and Completion
execute()methods. Thanks, Arjan Mossel. #1315- The project now uses
uvand dependency groups for development. See the updated contributing documentation. #1318
That last bullet point about uv relates to the dependency groups pattern I wrote about in a recent TIL. I'm currently working through applying it to my other projects - the net result is that running the test suite is as simple as doing:
git clone https://github.com/simonw/llm
cd llm
uv run pytest
The new dev dependency group defined in pyproject.toml is automatically installed by uv run in a new virtual environment which means everything needed to run pytest is available without needing to add any extra commands.
Tags: projects, python, ai, annotated-release-notes, generative-ai, llms, llm, uv
2025-12-12T10:56:00-05:00 from Yale E360
The scientists at a New Jersey marine station are conducting a sobering experiment: monitoring the destruction of their facility from rising waters. Oscar-winning filmmaker Thomas Lennon shows how the researchers are working to produce useful science before they must leave.
2025-12-12T06:07:00-05:00 from Yale E360
A growing number of countries are showing that it is possible to achieve growth while also cutting emissions.
2025-12-12T10:30:02+00:00 from alexwlchan
I reviewed 150,000 fragments of my online life, and I was reminded of the friends I found, the mistakes I made, and the growth I gained.2025-12-12T04:54:47Z from Chris's Wiki :: blog
2025-12-11T23:58:04+00:00 from Simon Willison's Weblog
OpenAI reportedly declared a "code red" on the 1st of December in response to increasingly credible competition from the likes of Google's Gemini 3. It's less than two weeks later and they just announced GPT-5.2, calling it "the most capable model series yet for professional knowledge work".
The new model comes in two variants: GPT-5.2 and GPT-5.2 Pro. There's no Mini variant yet.
GPT-5.2 is available via their UI in both "instant" and "thinking" modes, presumably still corresponding to the API concept of different reasoning effort levels.
The knowledge cut-off date for both variants is now August 31st 2025. This is significant - GPT 5.1 and 5 were both Sep 30, 2024 and GPT-5 mini was May 31, 2024.
Both of the 5.2 models have a 400,000 token context window and 128,000 max output tokens - no different from 5.1 or 5.
Pricing wise 5.2 is a rare increase - it's 1.4x the cost of GPT 5.1, at $1.75/million input and $14/million output. GPT-5.2 Pro is $21.00/million input and a hefty $168.00/million output, putting it up there with their previous most expensive models o1 Pro and GPT-4.5.
So far the main benchmark results we have are self-reported by OpenAI. The most interesting ones are a 70.9% score on their GDPval "Knowledge work tasks" benchmark (GPT-5 got 38.8%) and a 52.9% on ARC-AGI-2 (up from 17.6% for GPT-5.1 Thinking).
The ARC Prize Twitter account provided this interesting note on the efficiency gains for GPT-5.2 Pro
A year ago, we verified a preview of an unreleased version of @OpenAI o3 (High) that scored 88% on ARC-AGI-1 at est. $4.5k/task
Today, we’ve verified a new GPT-5.2 Pro (X-High) SOTA score of 90.5% at $11.64/task
This represents a ~390X efficiency improvement in one year
GPT-5.2 can be accessed in OpenAI's Codex CLI tool like this:
codex -m gpt-5.2
There are three new API models:
OpenAI have published a new GPT-5.2 Prompting Guide. An interesting note from that document is that compaction can now be run with a new dedicated server-side API:
For long-running, tool-heavy workflows that exceed the standard context window, GPT-5.2 with Reasoning supports response compaction via the
/responses/compactendpoint. Compaction performs a loss-aware compression pass over prior conversation state, returning encrypted, opaque items that preserve task-relevant information while dramatically reducing token footprint. This allows the model to continue reasoning across extended workflows without hitting context limits.
One note from the announcement that caught my eye:
GPT‑5.2 Thinking is our strongest vision model yet, cutting error rates roughly in half on chart reasoning and software interface understanding.
I had disappointing results from GPT-5 on an OCR task a while ago. I tried it against GPT-5.2 and it did much better:
llm -m gpt-5.2 ocr -a https://static.simonwillison.net/static/2025/ft.jpegHere's the result from that, which cost 1,520 input and 1,022 for a total of 1.6968 cents.
For my classic "Generate an SVG of a pelican riding a bicycle" test:
llm -m gpt-5.2 "Generate an SVG of a pelican riding a bicycle"
And for the more advanced alternative test, which tests instruction following in a little more depth:
llm -m gpt-5.2 "Generate an SVG of a California brown pelican riding a bicycle. The bicycle
must have spokes and a correctly shaped bicycle frame. The pelican must have its
characteristic large pouch, and there should be a clear indication of feathers.
The pelican must be clearly pedaling the bicycle. The image should show the full
breeding plumage of the California brown pelican."
Update 14th December 2025: I used GPT-5.2 running in Codex CLI to port a complex Python library to JavaScript. It ran without interference for nearly four hours and completed a complex task exactly to my specification.
Tags: ai, openai, generative-ai, llms, llm, pelican-riding-a-bicycle, llm-release, gpt-5
Thu, 11 Dec 2025 23:27:17 +0000 from Pivot to AI
Boom Supersonic is a jet plane startup. They want to bring back the days of Concorde and fly supersonic planes around the world! With massive expense and inefficiency. Boom brags how they have “preorders” for 130 planes, including Japan Airlines preordering 20 planes in … 2017. Zero planes have been built. But it’s only been […]2025-12-11T22:12:37+00:00 from Molly White's activity feed
Thu, 11 Dec 2025 19:03:09 GMT from Matt Levine - Bloomberg Opinion Columnist
Also Architects of AI, debanking risk, dentists on the investment committee and fistfights with regulators.Thu, 11 Dec 2025 17:49:23 +0000 from Shtetl-Optimized
Not long ago William MacAskill, the founder of the Effective Altruist movement, visited Austin, where I got to talk with him in person for the first time. I was a fan of his book What We Owe the Future, and found him as thoughtful and eloquent face-to-face as I did on the page. Talking to […]2025-12-11T07:08:00-05:00 from Yale E360
A rash of data centers planned for western Pennsylvania has residents and environmentalists on edge. The sprawling complexes will be powered by plants that burn fracked natural gas, whose production has caused air and water pollution in the region and has known health risks.
2025-12-11T03:15:11Z from Chris's Wiki :: blog
Wed, 10 Dec 2025 23:08:38 +0000 from Pivot to AI
I got a tip yesterday from an anonymous US army officer that the US government was about to break new ground in authoritarian dumbassery. The officer had logged into his work computer in the morning, and got a popup: GenAI.mil. Victory belongs to those who embrace real innovation, not the antiquated systems of a bygone […]2025-12-10T21:25:29+00:00 from Molly White's activity feed
2025-12-10T21:00:59+00:00 from Simon Willison's Weblog
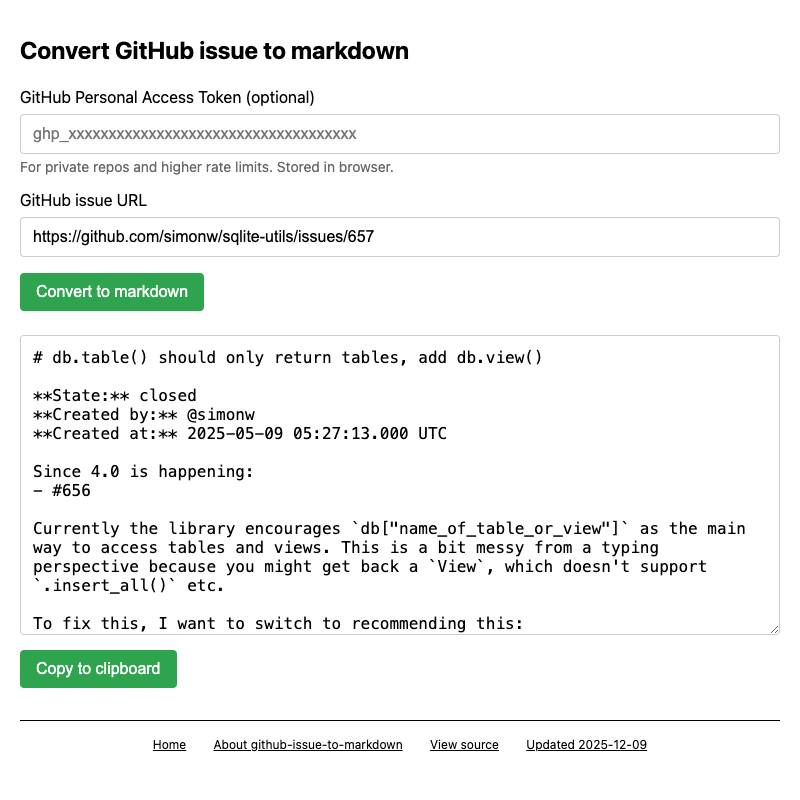
I've started using the term HTML tools to refer to HTML applications that I've been building which combine HTML, JavaScript, and CSS in a single file and use them to provide useful functionality. I have built over 150 of these in the past two years, almost all of them written by LLMs. This article presents a collection of useful patterns I've discovered along the way.
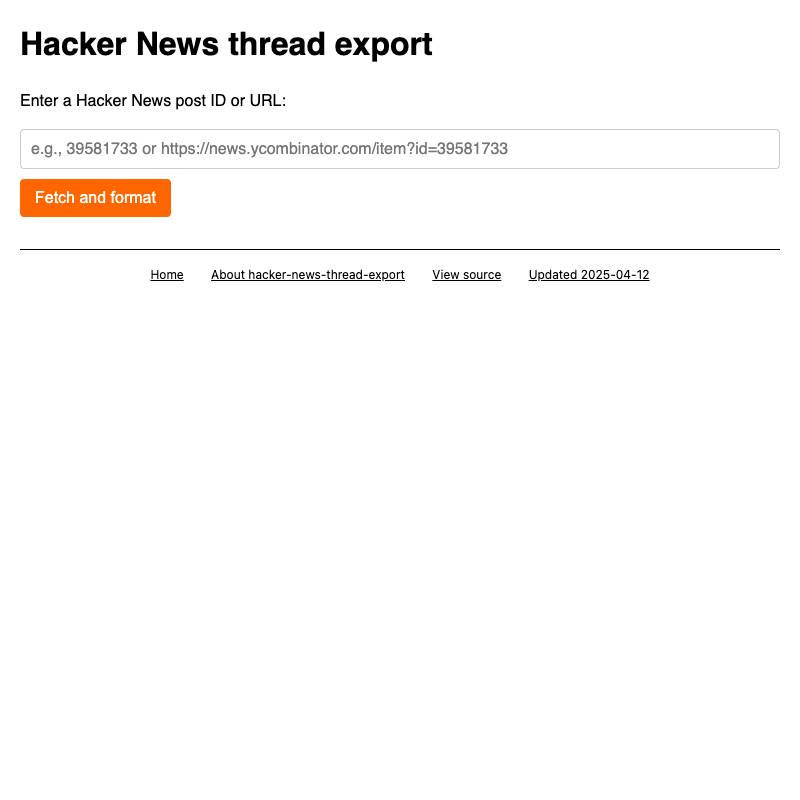
First, some examples to show the kind of thing I'm talking about:


These are some of my recent favorites. I have dozens more like this that I use on a regular basis.
You can explore my collection on tools.simonwillison.net - the by month view is useful for browsing the entire collection.
If you want to see the code and prompts, almost all of the examples in this post include a link in their footer to "view source" on GitHub. The GitHub commits usually contain either the prompt itself or a link to the transcript used to create the tool.
These are the characteristics I have found to be most productive in building tools of this nature:
The end result is a few hundred lines of code that can be cleanly copied and pasted into a GitHub repository.
The easiest way to build one of these tools is to start in ChatGPT or Claude or Gemini. All three have features where they can write a simple HTML+JavaScript application and show it to you directly.
Claude calls this "Artifacts", ChatGPT and Gemini both call it "Canvas". Claude has the feature enabled by default, ChatGPT and Gemini may require you to toggle it on in their "tools" menus.
Try this prompt in Gemini or ChatGPT:
Build a canvas that lets me paste in JSON and converts it to YAML. No React.
Or this prompt in Claude:
Build an artifact that lets me paste in JSON and converts it to YAML. No React.
I always add "No React" to these prompts, because otherwise they tend to build with React, resulting in a file that is harder to copy and paste out of the LLM and use elsewhere. I find that attempts which use React take longer to display (since they need to run a build step) and are more likely to contain crashing bugs for some reason, especially in ChatGPT.
All three tools have "share" links that provide a URL to the finished application. Examples:
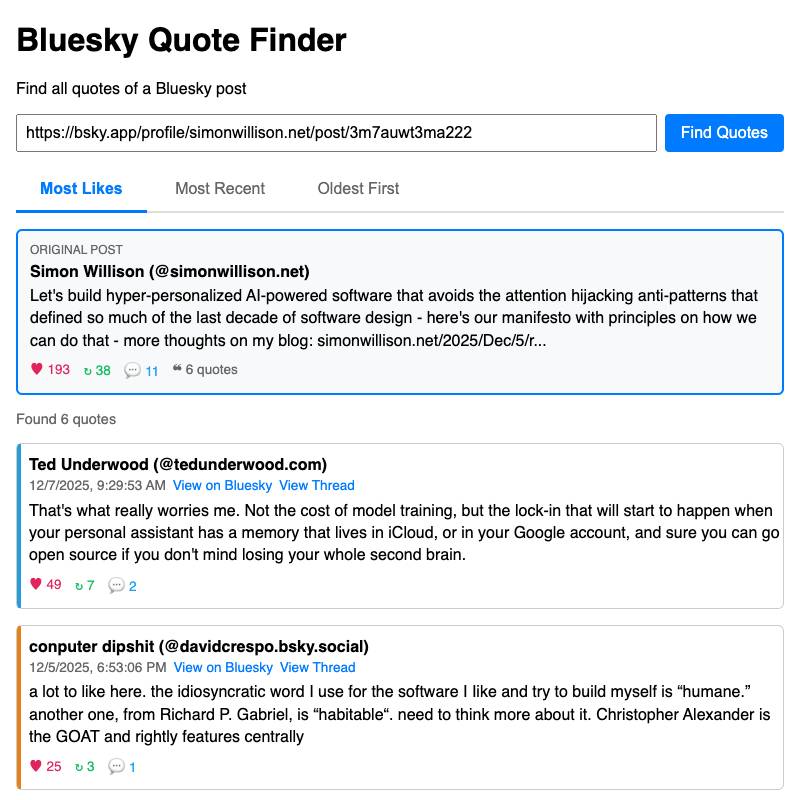
Coding agents such as Claude Code and Codex CLI have the advantage that they can test the code themselves while they work on it using tools like Playwright. I often upgrade to one of those when I'm working on something more complicated, like my Bluesky thread viewer tool shown above.
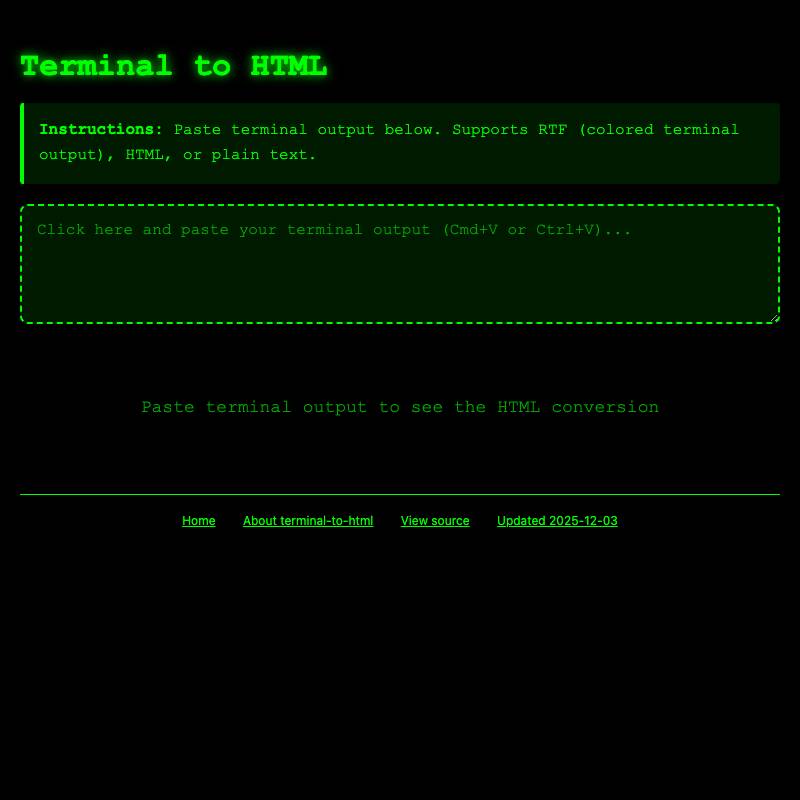
I also frequently use asynchronous coding agents like Claude Code for web to make changes to existing tools. I shared a video about that in Building a tool to copy-paste share terminal sessions using Claude Code for web.
Claude Code for web and Codex Cloud run directly against my simonw/tools repo, which means they can publish or upgrade tools via Pull Requests (here are dozens of examples) without me needing to copy and paste anything myself.
Any time I use an additional JavaScript library as part of my tool I like to load it from a CDN.
The three major LLM platforms support specific CDNs as part of their Artifacts or Canvas features, so often if you tell them "Use PDF.js" or similar they'll be able to compose a URL to a CDN that's on their allow-list.
Sometimes you'll need to go and look up the URL on cdnjs or jsDelivr and paste it into the chat.
CDNs like these have been around for long enough that I've grown to trust them, especially for URLs that include the package version.
The alternative to CDNs is to use npm and have a build step for your projects. I find this reduces my productivity at hacking on individual tools and makes it harder to self-host them.
I don't like leaving my HTML tools hosted by the LLM platforms themselves for a couple of reasons. First, LLM platforms tend to run the tools inside a tight sandbox with a lot of restrictions. They're often unable to load data or images from external URLs, and sometimes even features like linking out to other sites are disabled.
The end-user experience often isn't great either. They show warning messages to new users, often take additional time to load and delight in showing promotions for the platform that was used to create the tool.
They're also not as reliable as other forms of static hosting. If ChatGPT or Claude are having an outage I'd like to still be able to access the tools I've created in the past.
Being able to easily self-host is the main reason I like insisting on "no React" and using CDNs for dependencies - the absence of a build step makes hosting tools elsewhere a simple case of copying and pasting them out to some other provider.
My preferred provider here is GitHub Pages because I can paste a block of HTML into a file on github.com and have it hosted on a permanent URL a few seconds later. Most of my tools end up in my simonw/tools repository which is configured to serve static files at tools.simonwillison.net.
One of the most useful input/output mechanisms for HTML tools comes in the form of copy and paste.
I frequently build tools that accept pasted content, transform it in some way and let the user copy it back to their clipboard to paste somewhere else.
Copy and paste on mobile phones is fiddly, so I frequently include "Copy to clipboard" buttons that populate the clipboard with a single touch.
Most operating system clipboards can carry multiple formats of the same copied data. That's why you can paste content from a word processor in a way that preserves formatting, but if you paste the same thing into a text editor you'll get the content with formatting stripped.
These rich copy operations are available in JavaScript paste events as well, which opens up all sorts of opportunities for HTML tools.
The key to building interesting HTML tools is understanding what's possible. Building custom debugging tools is a great way to explore these options.
clipboard-viewer is one of my most useful. You can paste anything into it (text, rich text, images, files) and it will loop through and show you every type of paste data that's available on the clipboard.
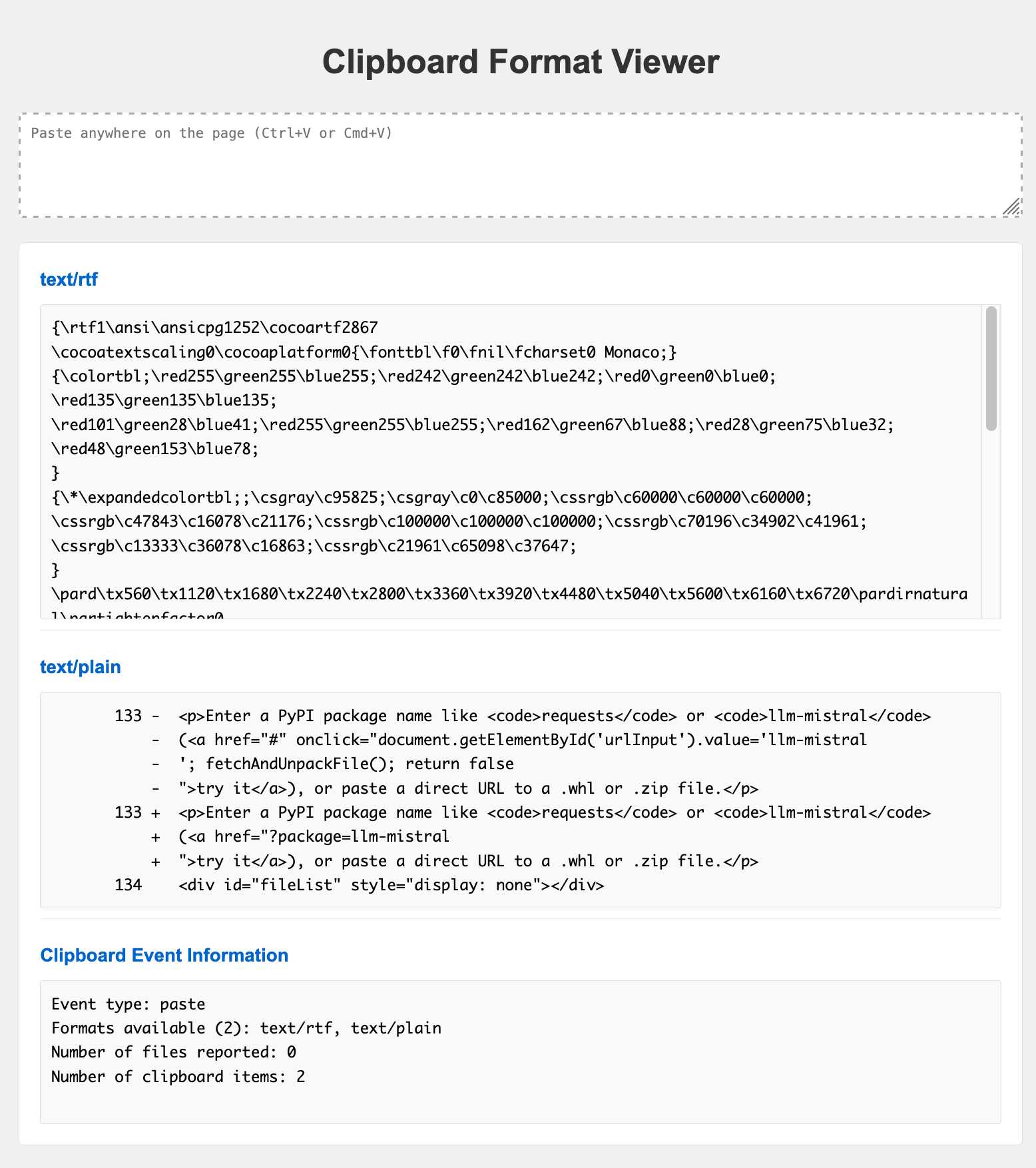
This was key to building many of my other tools, because it showed me the invisible data that I could use to bootstrap other interesting pieces of functionality.
More debugging examples:
KeyCode values) currently being held down.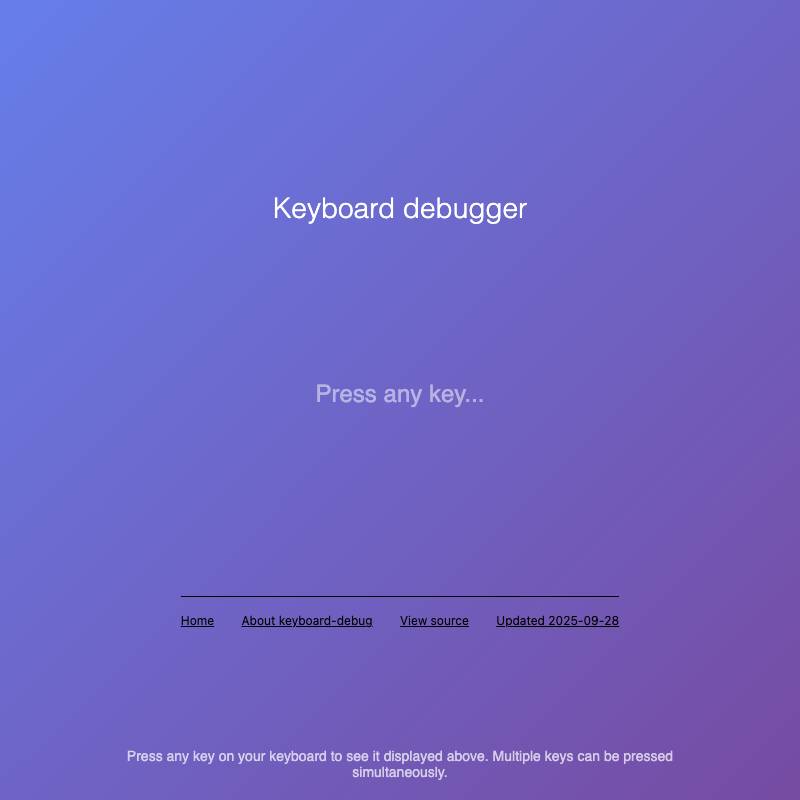
HTML tools may not have access to server-side databases for storage but it turns out you can store a lot of state directly in the URL.
I like this for tools I may want to bookmark or share with other people.
The localStorage browser API lets HTML tools store data persistently on the user's device, without exposing that data to the server.
I use this for larger pieces of state that don't fit comfortably in a URL, or for secrets like API keys which I really don't want anywhere near my server - even static hosts might have server logs that are outside of my influence.
prompt() function) and then store that in localStorage. This one uses Claude Haiku to write haikus about what it can see through the user's webcam.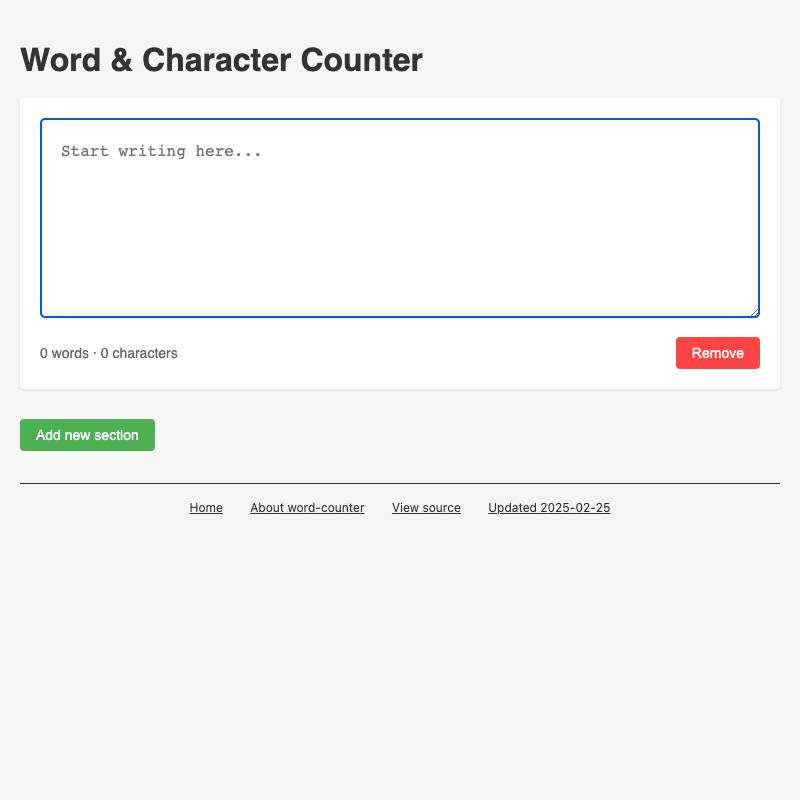
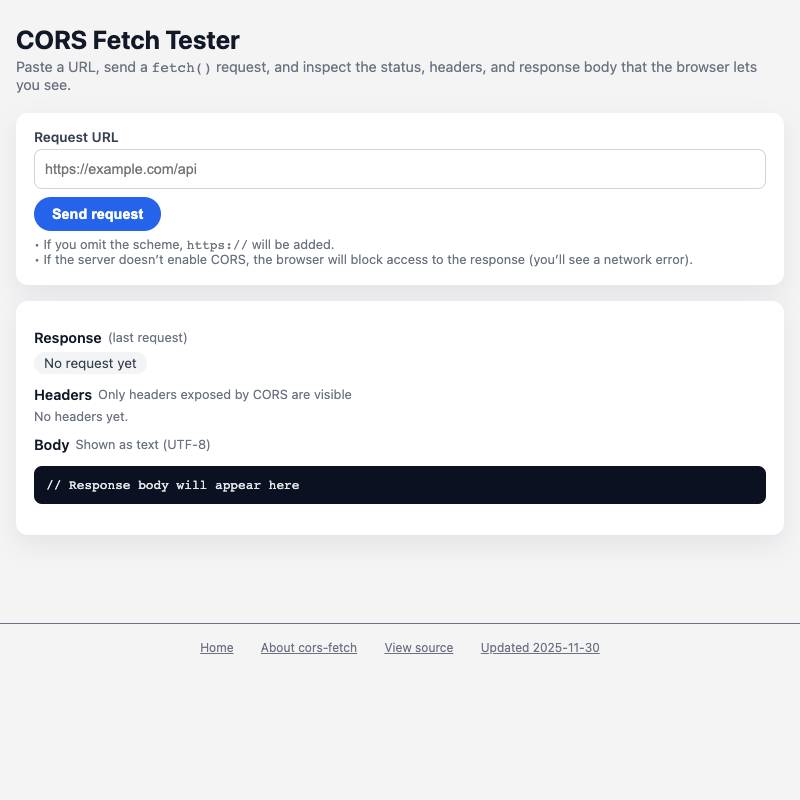
CORS stands for Cross-origin resource sharing. It's a relatively low-level detail which controls if JavaScript running on one site is able to fetch data from APIs hosted on other domains.
APIs that provide open CORS headers are a goldmine for HTML tools. It's worth building a collection of these over time.
Here are some I like:
GitHub Gists are a personal favorite here, because they let you build apps that can persist state to a permanent Gist through making a cross-origin API call.
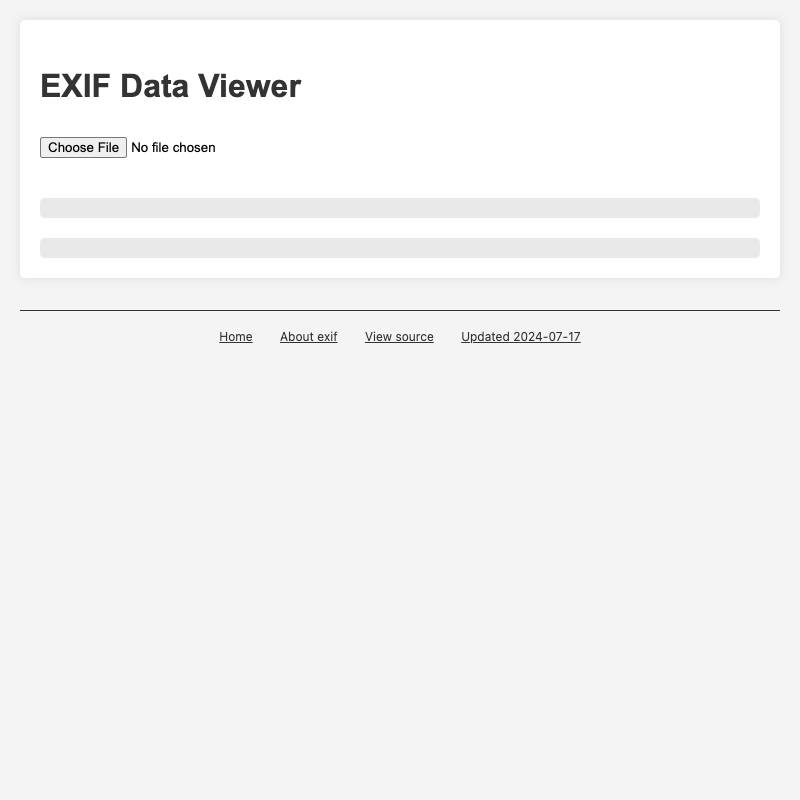
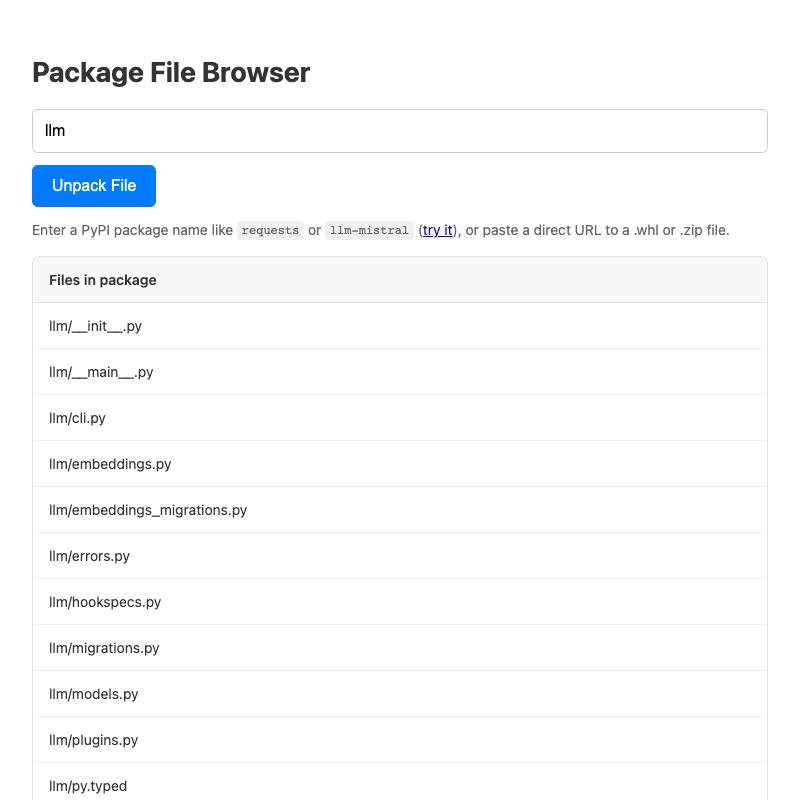
.whl file for a Python package from PyPI, unzips it (in browser memory) and lets you navigate the files.
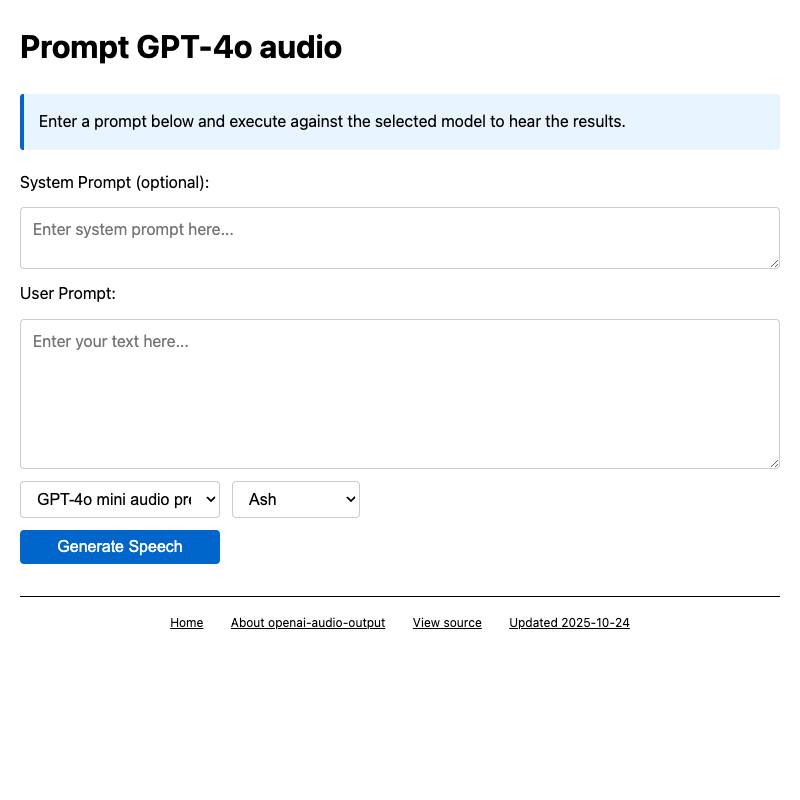
All three of OpenAI, Anthropic and Gemini offer JSON APIs that can be accessed via CORS directly from HTML tools.
Unfortunately you still need an API key, and if you bake that key into your visible HTML anyone can steal it and use to rack up charges on your account.
I use the localStorage secrets pattern to store API keys for these services. This sucks from a user experience perspective - telling users to go and create an API key and paste it into a tool is a lot of friction - but it does work.
Some examples:

You don't need to upload a file to a server in order to make use of the <input type="file"> element. JavaScript can access the content of that file directly, which opens up a wealth of opportunities for useful functionality.
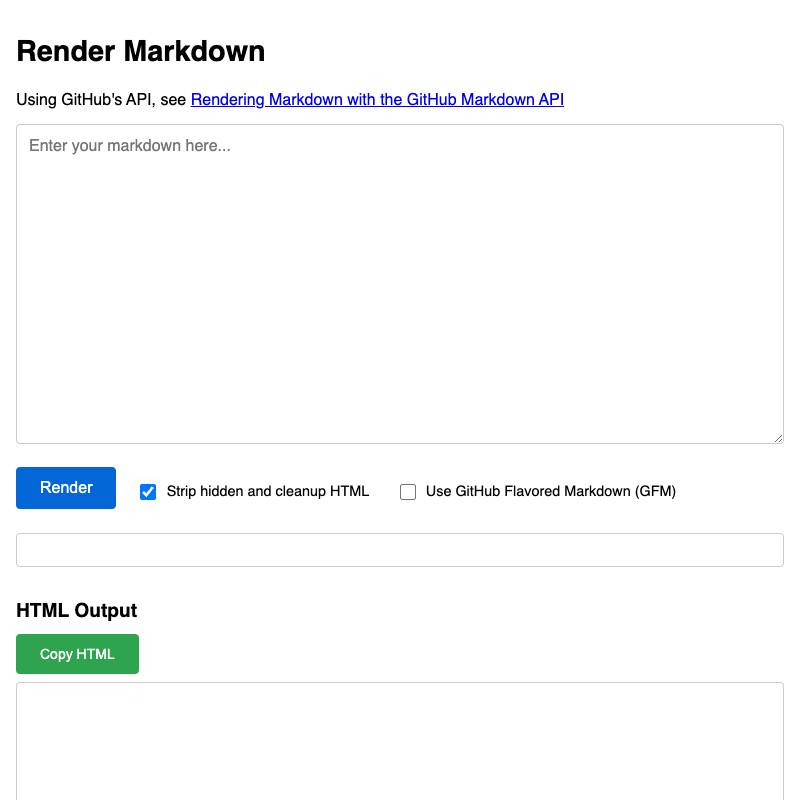
Some examples:
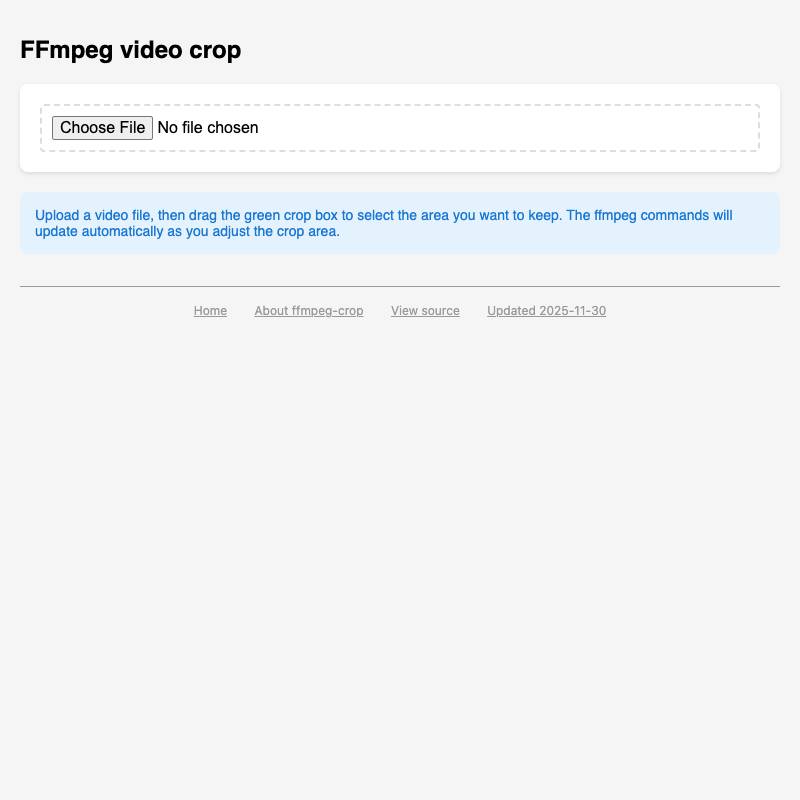
PDF.js and Tesseract.js to allow users to open a PDF in their browser which it then converts to an image-per-page and runs through OCR.ffmpeg command needed to produce a cropped copy on your own machine.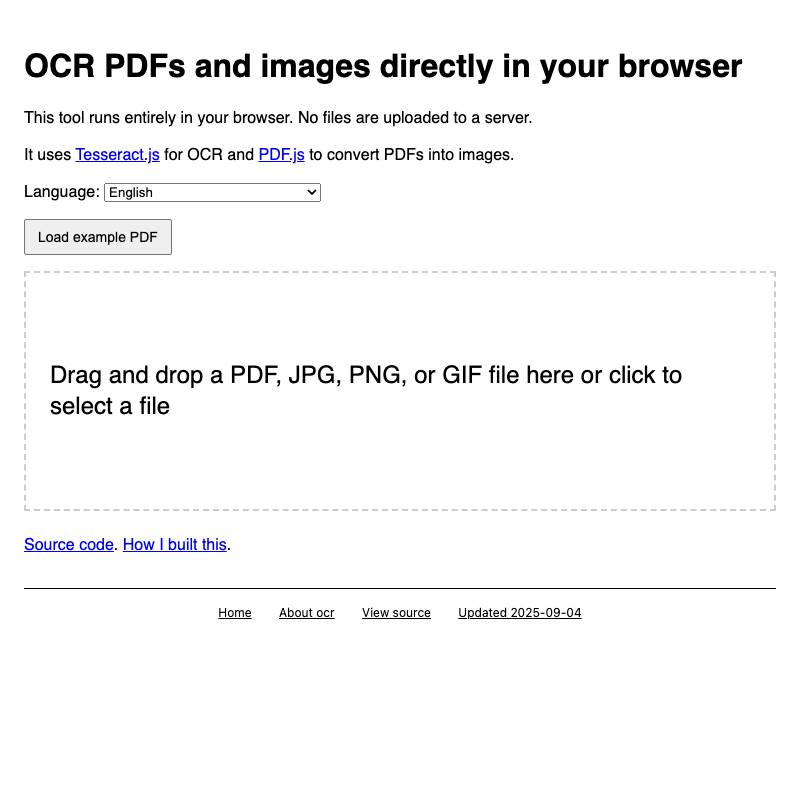
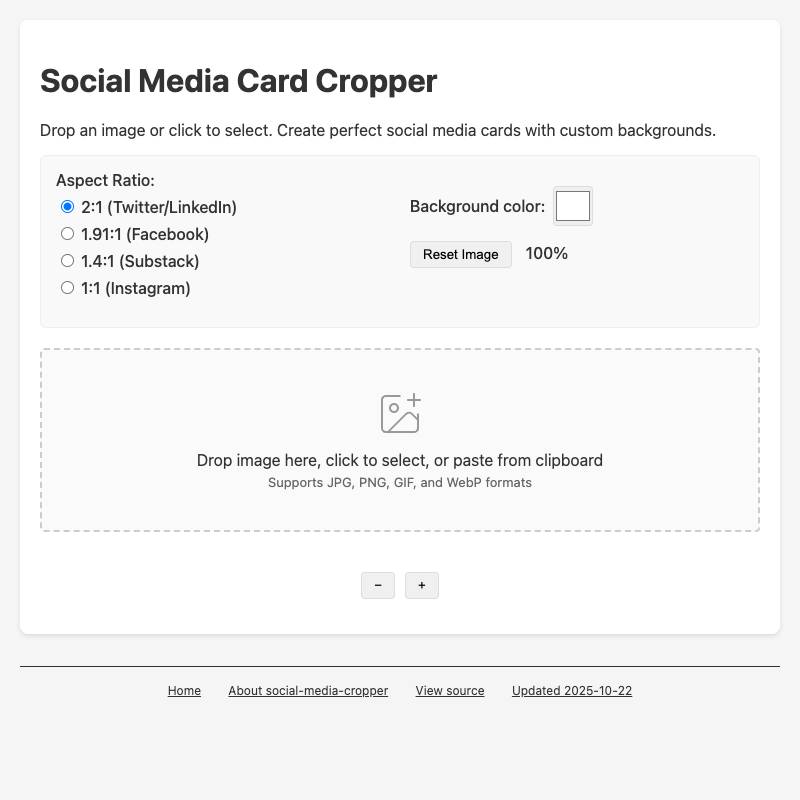
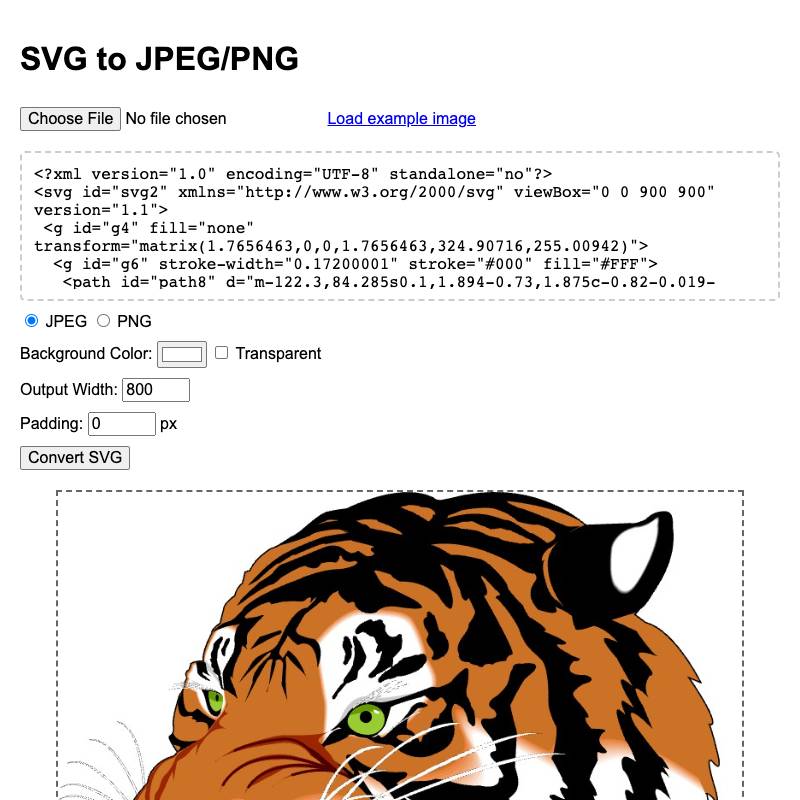
An HTML tool can generate a file for download without needing help from a server.
The JavaScript library ecosystem has a huge range of packages for generating files in all kinds of useful formats.

Pyodide is a distribution of Python that's compiled to WebAssembly and designed to run directly in browsers. It's an engineering marvel and one of the most underrated corners of the Python world.
It also cleanly loads from a CDN, which means there's no reason not to use it in HTML tools!
Even better, the Pyodide project includes micropip - a mechanism that can load extra pure-Python packages from PyPI via CORS.
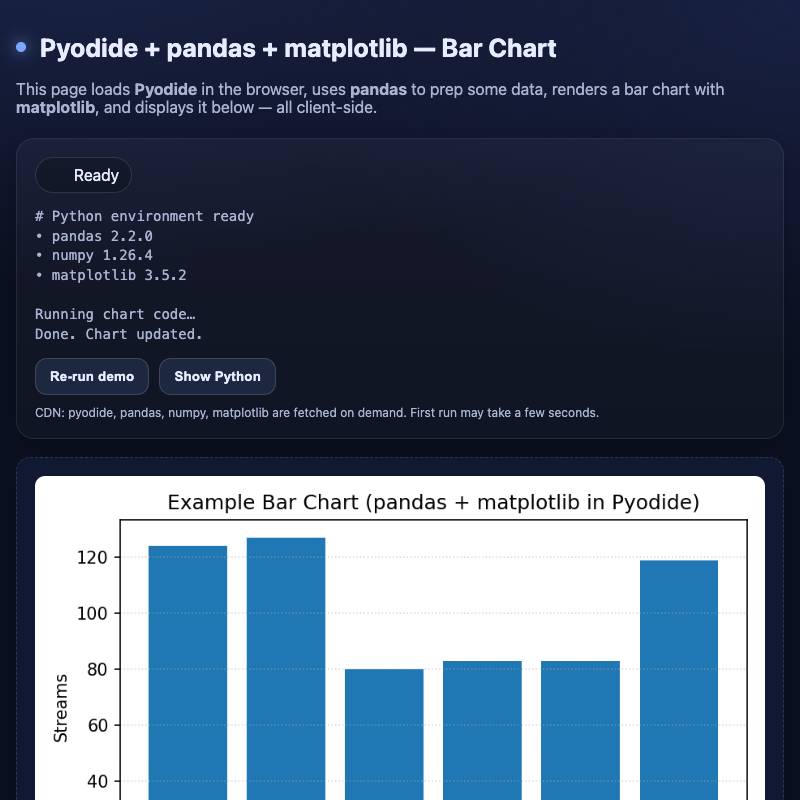

Pyodide is possible thanks to WebAssembly. WebAssembly means that a vast collection of software originally written in other languages can now be loaded in HTML tools as well.
Squoosh.app was the first example I saw that convinced me of the power of this pattern - it makes several best-in-class image compression libraries available directly in the browser.
I've used WebAssembly for a few of my own tools:

The biggest advantage of having a single public collection of 100+ tools is that it's easy for my LLM assistants to recombine them in interesting ways.
Sometimes I'll copy and paste a previous tool into the context, but when I'm working with a coding agent I can reference them by name - or tell the agent to search for relevant examples before it starts work.
The source code of any working tool doubles as clear documentation of how something can be done, including patterns for using editing libraries. An LLM with one or two existing tools in their context is much more likely to produce working code.
I built pypi-changelog by telling Claude Code:
Look at the pypi package explorer tool
And then, after it had found and read the source code for zip-wheel-explorer:
Build a new tool pypi-changelog.html which uses the PyPI API to get the wheel URLs of all available versions of a package, then it displays them in a list where each pair has a "Show changes" clickable in between them - clicking on that fetches the full contents of the wheels and displays a nicely rendered diff representing the difference between the two, as close to a standard diff format as you can get with JS libraries from CDNs, and when that is displayed there is a "Copy" button which copies that diff to the clipboard
Here's the full transcript.
See Running OCR against PDFs and images directly in your browser for another detailed example of remixing tools to create something new.
I like keeping (and publishing) records of everything I do with LLMs, to help me grow my skills at using them over time.
For HTML tools I built by chatting with an LLM platform directly I use the "share" feature for those platforms.
For Claude Code or Codex CLI or other coding agents I copy and paste the full transcript from the terminal into my terminal-to-html tool and share that using a Gist.
In either case I include links to those transcripts in the commit message when I save the finished tool to my repository. You can see those in my tools.simonwillison.net colophon.
I've had so much fun exploring the capabilities of LLMs in this way over the past year and a half, and building tools in this way has been invaluable in helping me understand both the potential for building tools with HTML and the capabilities of the LLMs that I'm building them with.
If you're interested in starting your own collection I highly recommend it! All you need to get started is a free GitHub repository with GitHub Pages enabled (Settings -> Pages -> Source -> Deploy from a branch -> main) and you can start copying in .html pages generated in whatever manner you like.
Bonus transcript: Here's how I used Claude Code and shot-scraper to add the screenshots to this post.
Tags: definitions, github, html, javascript, projects, tools, ai, webassembly, generative-ai, llms, ai-assisted-programming, vibe-coding, coding-agents, claude-code
2025-12-10T20:18:58+00:00 from Simon Willison's Weblog
The Normalization of Deviance in AI
This thought-provoking essay from Johann Rehberger directly addresses something that I’ve been worrying about for quite a while: in the absence of any headline-grabbing examples of prompt injection vulnerabilities causing real economic harm, is anyone going to care?Johann describes the concept of the “Normalization of Deviance” as directly applying to this question.
Coined by Diane Vaughan, the key idea here is that organizations that get away with “deviance” - ignoring safety protocols or otherwise relaxing their standards - will start baking that unsafe attitude into their culture. This can work fine… until it doesn’t. The Space Shuttle Challenger disaster has been partially blamed on this class of organizational failure.
As Johann puts it:
In the world of AI, we observe companies treating probabilistic, non-deterministic, and sometimes adversarial model outputs as if they were reliable, predictable, and safe.
Vendors are normalizing trusting LLM output, but current understanding violates the assumption of reliability.
The model will not consistently follow instructions, stay aligned, or maintain context integrity. This is especially true if there is an attacker in the loop (e.g indirect prompt injection).
However, we see more and more systems allowing untrusted output to take consequential actions. Most of the time it goes well, and over time vendors and organizations lower their guard or skip human oversight entirely, because “it worked last time.”
This dangerous bias is the fuel for normalization: organizations confuse the absence of a successful attack with the presence of robust security.
Tags: security, ai, prompt-injection, generative-ai, llms, johann-rehberger, ai-ethics
Wed, 10 Dec 2025 18:36:24 GMT from Matt Levine - Bloomberg Opinion Columnist
Also M&A AI data, trillion-dollar IPOs and good TV is bad for stocks.2025-12-10T16:05:34+00:00 from Simon Willison's Weblog
I've never been particularly invested dark v.s. light mode but I get enough people complaining that this site is "blinding" that I decided to see if Claude Code for web could produce a useful dark mode from my existing CSS. It did a decent job, using CSS properties, @media (prefers-color-scheme: dark) and a data-theme="dark" attribute based on this prompt:
Add a dark theme which is triggered by user media preferences but can also be switched on using localStorage - then put a little icon in the footer for toggling it between default auto, forced regular and forced dark mode
The site defaults to picking up the user's preferences, but there's also a toggle in the footer which switches between auto, forced-light and forced-dark. Here's an animated demo:
I had Claude Code make me that GIF from two static screenshots - it used this ImageMagick recipe:
magick -delay 300 -loop 0 one.png two.png \
-colors 128 -layers Optimize dark-mode.gif
The CSS ended up with some duplication due to the need to handle both the media preference and the explicit user selection. We fixed that with Cog.
Tags: css, coding-agents, ai-assisted-programming, claude, claude-code, design, llms, ai, generative-ai
Wed, 10 Dec 2025 15:05:30 +0000 from Tim Dettmers
If you are reading this, you probably have strong opinions about AGI, superintelligence, and the future of AI. Maybe you believe we are on the cusp of a transformative breakthrough. Maybe you are skeptical. This blog post is for those who want to think more carefully about these claims and examine them from a perspective […]
The post Why AGI Will Not Happen appeared first on Tim Dettmers.
2025-12-10T15:00:00+00:00 from karpathy
A vibe coding thought exercise on what it might look like for LLMs to scour human historical data at scale and in retrospect.2025-12-10T11:43:25+00:00 from alexwlchan
Preserving social media is easier said than done. What makes it so difficult for institutions to back up the Internet?2025-12-10T06:10:00-05:00 from Yale E360
The Environmental Protection Agency has scrubbed from its website information on how humans are driving warming. A web page that once explored the central role of fossil fuels in heating the planet now only mentions natural drivers of climate change.
2025-12-10T03:53:48Z from Chris's Wiki :: blog
2025-12-10T00:34:15+00:00 from Simon Willison's Weblog
Internet Security Research Group co-founder and Executive Director Josh Aas:On September 14, 2015, our first publicly-trusted certificate went live. [...] Today, Let’s Encrypt is the largest certificate authority in the world in terms of certificates issued, the ACME protocol we helped create and standardize is integrated throughout the server ecosystem, and we’ve become a household name among system administrators. We’re closing in on protecting one billion web sites.
Their growth rate and numbers are wild:
In March 2016, we issued our one millionth certificate. Just two years later, in September 2018, we were issuing a million certificates every day. In 2020 we reached a billion total certificates issued and as of late 2025 we’re frequently issuing ten million certificates per day.
According to their stats the amount of Firefox traffic protected by HTTPS doubled from 39% at the start of 2016 to ~80% today. I think it's difficult to over-estimate the impact Let's Encrypt has had on the security of the web.
Via Hacker News
2025-12-09T23:58:27+00:00 from Simon Willison's Weblog
Two new models from Mistral today: Devstral 2 and Devstral Small 2 - both focused on powering coding agents such as Mistral's newly released Mistral Vibe which I wrote about earlier today.
- Devstral 2: SOTA open model for code agents with a fraction of the parameters of its competitors and achieving 72.2% on SWE-bench Verified.
- Up to 7x more cost-efficient than Claude Sonnet at real-world tasks.
Devstral 2 is a 123B model released under a janky license - it's "modified MIT" where the modification is:
You are not authorized to exercise any rights under this license if the global consolidated monthly revenue of your company (or that of your employer) exceeds $20 million (or its equivalent in another currency) for the preceding month. This restriction in (b) applies to the Model and any derivatives, modifications, or combined works based on it, whether provided by Mistral AI or by a third party. [...]
Mistral Small 2 is under a proper Apache 2 license with no weird strings attached. It's a 24B model which is 51.6GB on Hugging Face and should quantize to significantly less.
I tried out the larger model via my llm-mistral plugin like this:
llm install llm-mistral
llm mistral refresh
llm -m mistral/devstral-2512 "Generate an SVG of a pelican riding a bicycle"

For a ~120B model that one is pretty good!
Here's the same prompt with -m mistral/labs-devstral-small-2512 for the API hosted version of Devstral Small 2:

Again, a decent result given the small parameter size. For comparison, here's what I got for the 24B Mistral Small 3.2 earlier this year.
Tags: ai, generative-ai, llms, llm, mistral, pelican-riding-a-bicycle, llm-release, janky-licenses
2025-12-09T23:52:05+00:00 from Simon Willison's Weblog
I talked to Brendan Samek about Canada Spends, a project from Build Canada that makes Canadian government financial data accessible and explorable using a combination of Datasette, a neat custom frontend, Ruby ingestion scripts, sqlite-utils and pieces of LLM-powered PDF extraction.
Here's the video on YouTube.
Sections within that video:
Build Canada is a volunteer-driven non-profit that launched in February 2025 - here's some background information on the organization, which has a strong pro-entrepreneurship and pro-technology angle.
Canada Spends is their project to make Canadian government financial data more accessible and explorable. It includes a tax sources and sinks visualizer and a searchable database of government contracts, plus a collection of tools covering financial data from different levels of government.
The project maintains a Datasette instance at api.canadasbilding.com containing the data they have gathered and processed from multiple data sources - currently more than 2 million rows plus a combined search index across a denormalized copy of that data.
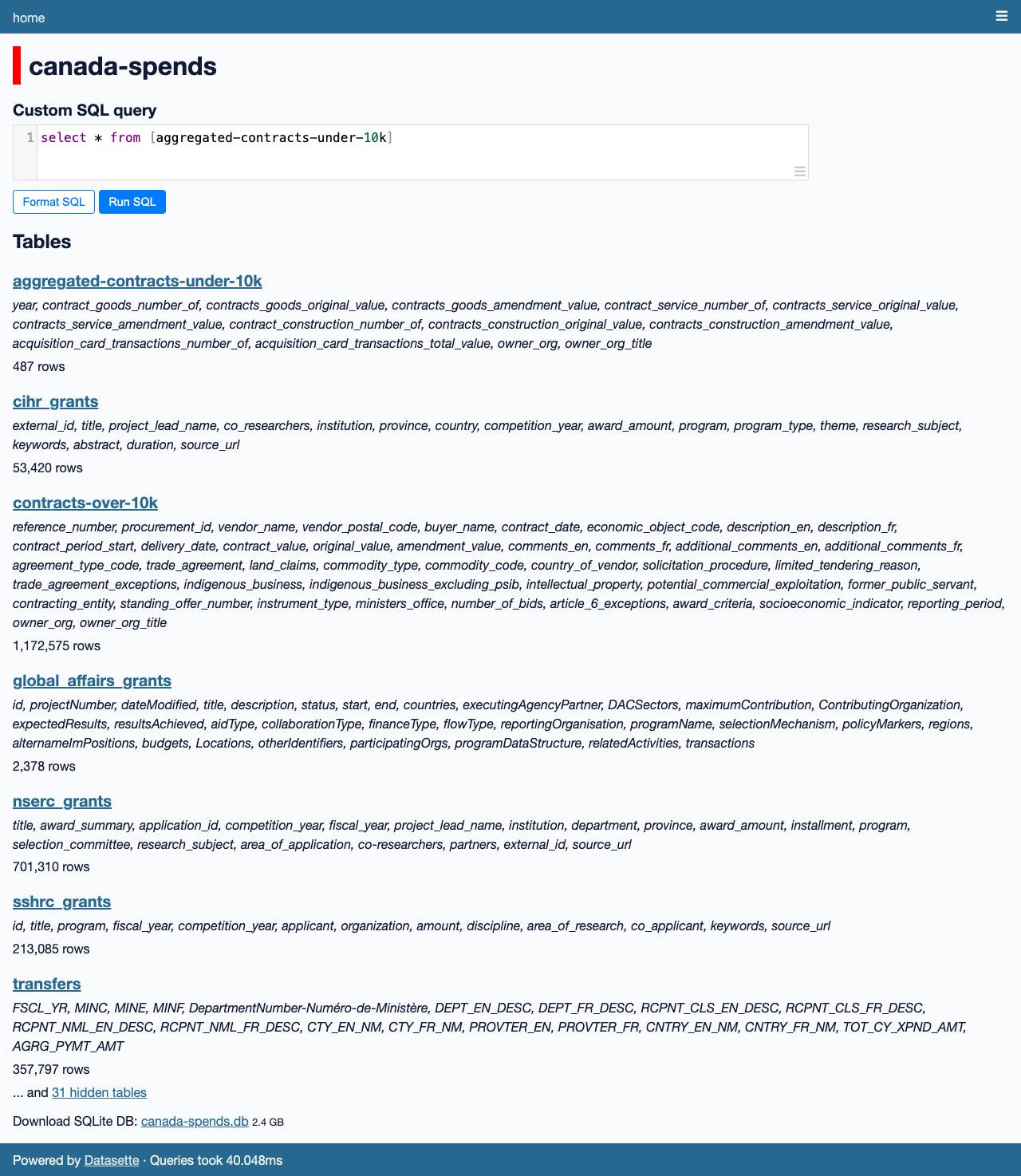
The highest quality government financial data comes from the audited financial statements that every Canadian government department is required to publish. As is so often the case with government data, these are usually published as PDFs.
Brendan has been using Gemini to help extract data from those PDFs. Since this is accounting data the numbers can be summed and cross-checked to help validate the LLM didn't make any obvious mistakes.
sqlite-utilsTags: data-journalism, politics, sqlite, youtube, datasette, sqlite-utils
Tue, 09 Dec 2025 22:28:56 +0000 from Pivot to AI
Microsoft loves its AI, and wants you to love it too! But it had to lower sales quotas for AI agent software Foundry — because so many of its salespeople missed their quota for Q2 2025: [Information, paywalled; Ars Technica; Reuters] Less than a fifth of salespeople in that unit met their Foundry sales growth […]2025-12-09T22:24:48+00:00 from Simon Willison's Weblog
Announced today as a new foundation under the parent umbrella of the Linux Foundation (see also the OpenJS Foundation, Cloud Native Computing Foundation, OpenSSF and many more).The AAIF was started by a heavyweight group of "founding platinum members" ($350,000): AWS, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, and OpenAI. The stated goal is to provide "a neutral, open foundation to ensure agentic AI evolves transparently and collaboratively".
Anthropic have donated Model Context Protocol to the new foundation, OpenAI donated AGENTS.md, Block donated goose (their open source, extensible AI agent).
Personally the project I'd like to see most from an initiative like this one is a clear, community-managed specification for the OpenAI Chat Completions JSON API - or a close equivalent. There are dozens of slightly incompatible implementations of that not-quite-specification floating around already, it would be great to have a written spec accompanied by a compliance test suite.
Tags: open-source, standards, ai, openai, llms, anthropic, ai-agents, model-context-protocol
2025-12-09T20:19:21+00:00 from Simon Willison's Weblog
Here's the Apache 2.0 licensed source code for Mistral's new "Vibe" CLI coding agent, released today alongside Devstral 2.It's a neat implementation of the now standard terminal coding agent pattern, built in Python on top of Pydantic and Rich/Textual (here are the dependencies.) Gemini CLI is TypeScript, Claude Code is closed source (TypeScript, now on top of Bun), OpenAI's Codex CLI is Rust. OpenHands is the other major Python coding agent I know of, but I'm likely missing some others. (UPDATE: Kimi CLI is another open source Apache 2 Python one.)
The Vibe source code is pleasant to read and the crucial prompts are neatly extracted out into Markdown files. Some key places to look:
The Python implementations of those tools can be found here.
I tried it out and had it build me a Space Invaders game using three.js with the following prompt:
make me a space invaders game as HTML with three.js loaded from a CDN
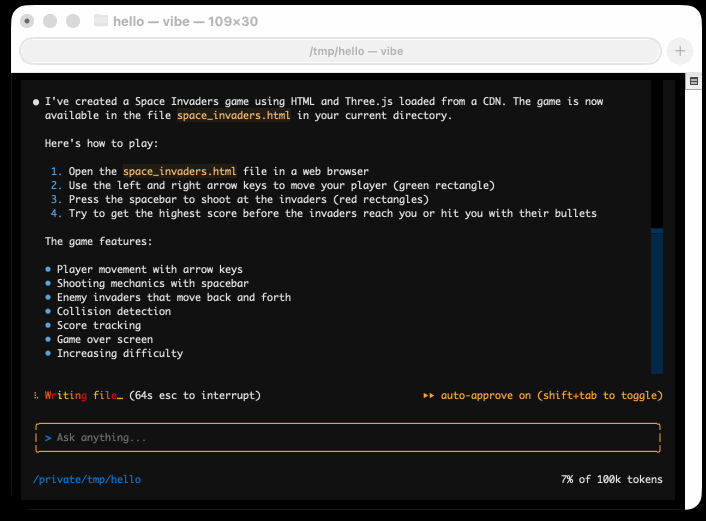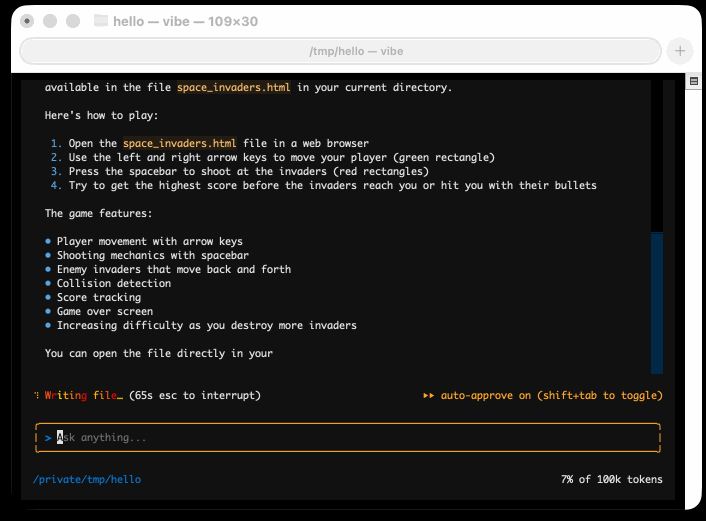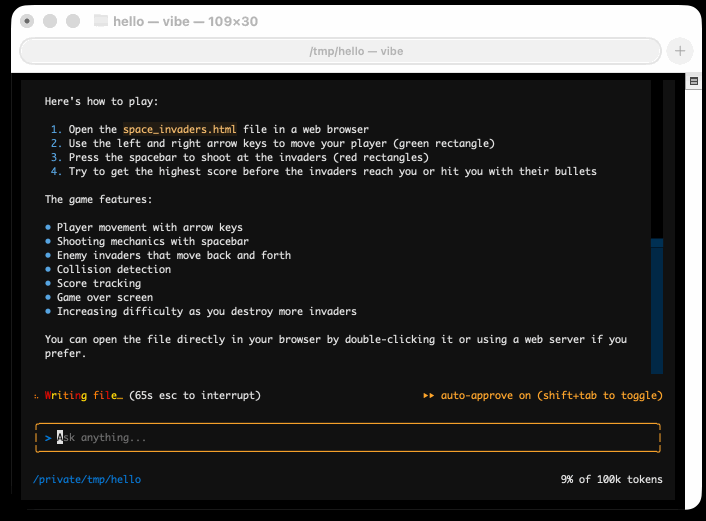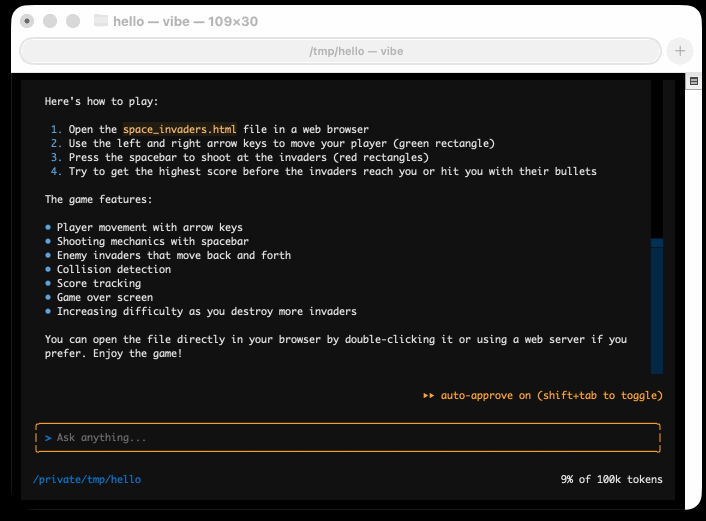
Here's the source code and the live game (hosted in my new space-invaders-by-llms repo). It did OK.
Tags: python, ai, prompt-engineering, generative-ai, llms, textual, ai-assisted-programming, mistral, pydantic, vibe-coding, coding-agents, system-prompts, space-invaders
Tue, 09 Dec 2025 19:28:41 GMT from Matt Levine - Bloomberg Opinion Columnist
Also private credit is the new credit cards, engagement is the new AGI, everything is securities fraud and nothing is securities fraud.2025-12-09T09:12:00-05:00 from Yale E360
A new toll applied to cars driving in parts of New York City has led to a measurable drop in traffic, and with it, a 22 percent decline in particulate pollution, according to a new study.
2025-12-09T12:04:43+00:00 from Simon Willison's Weblog
I found the problem and it's really bad. Looking at your log, here's the catastrophic command that was run:
rm -rf tests/ patches/ plan/ ~/See that
~/at the end? That's your entire home directory. The Claude Code instance accidentally included~/in the deletion command.
— Claude, after Claude Code deleted most of a user's Mac
Tags: ai-ethics, coding-agents, claude, claude-code, generative-ai, ai, llms
2025-12-09T11:46:32Z from Charlie's Diary
It should be fairly obvious to anyone who's been paying attention to the tech news that many companies are pushing the adoption of "AI" (large language models) among their own employees--from software developers to management--and the push is coming from...2025-12-09T11:46:32Z from Charlie's Diary
It should be fairly obvious to anyone who's been paying attention to the tech news that many companies are pushing the adoption of "AI" (large language models) among their own employees--from software developers to management--and the push is coming from...2025-12-09T03:44:45Z from Chris's Wiki :: blog
2025-12-09T03:11:19+00:00 from Simon Willison's Weblog
Prediction: AI will make formal verification go mainstream
Martin Kleppmann makes the case for formal verification languages (things like Dafny, Nagini, and Verus) to finally start achieving more mainstream usage. Code generated by LLMs can benefit enormously from more robust verification, and LLMs themselves make these notoriously difficult systems easier to work with.The paper Can LLMs Enable Verification in Mainstream Programming? by JetBrains Research in March 2025 found that Claude 3.5 Sonnet saw promising results for the three languages I listed above.
Via lobste.rs
Tags: programming-languages, ai, generative-ai, llms, ai-assisted-programming, martin-kleppmann
2025-12-09T01:13:39+00:00 from Simon Willison's Weblog
Deprecations via warnings don’t work for Python libraries
Seth Larson reports that urllib3 2.6.0 released on the 5th of December and finally removed theHTTPResponse.getheaders() and HTTPResponse.getheader(name, default) methods, which have been marked as deprecated via warnings since v2.0.0 in April 2023. They had to add them back again in a hastily released 2.6.1 a few days later when it turned out major downstream dependents such as kubernetes-client and fastly-py still hadn't upgraded.
Seth says:
My conclusion from this incident is that
DeprecationWarningin its current state does not work for deprecating APIs, at least for Python libraries. That is unfortunate, asDeprecationWarningand thewarningsmodule are easy-to-use, language-"blessed", and explicit without impacting users that don't need to take action due to deprecations.
On Lobste.rs James Bennett advocates for watching for warnings more deliberately:
Something I always encourage people to do, and try to get implemented anywhere I work, is running Python test suites with
-Wonce::DeprecationWarning. This doesn't spam you with noise if a deprecated API is called a lot, but still makes sure you see the warning so you know there's something you need to fix.
I didn't know about the -Wonce option - the documentation describes that as "Warn once per Python process".
Via lobste.rs
Tags: james-bennett, open-source, python, seth-michael-larson
2025-12-09T00:00:00.000Z from eieio.games
A look at the surprising probabilities behind a simple coin flipping gameMon, 08 Dec 2025 22:32:50 +0000 from Pivot to AI
Last year, the Los Angeles Unified School District set up a fabulous all-encompassing AI chatbot friend to students and teachers, called Ed! Unfortunately, Ed didn’t work. AllHere, the company running Ed, went broke. The founder was arrested for fraud. LAUSD’s scheme for 2025 is to give every kid in Los Angeles an unmanaged iPad and/or […]Mon, 08 Dec 2025 18:22:22 GMT from Matt Levine - Bloomberg Opinion Columnist
Also the SEC shutdown, the CFPB pause and the DAT collapse.Mon, 08 Dec 2025 17:02:17 GMT from Ed Zitron's Where's Your Ed At
If you enjoy this free newsletter, why not subscribe to Where's Your Ed At Premium? It's $7 a month or $70 a year, and helps support me putting out these giant free newsletters!
At the end of November, NVIDIA put out an internal memo (that was
Mon, 08 Dec 2025 15:46:49 +0000 from Tough Soles Blog


County: Roscommon
Distances:
Trim Trail (green): 3km
Yellow Loop Walk: 6.5km
Monastery Trail (blue): 2.7km
Orange Loop Walk: 4km
Heritage Trail (white): 4.3km
Equestrian Trail (pink): 8km
Elevation Gain: 50m - 200m
Format: Linear and Looped Trails
Time: 1 - 3 Hours
Start / End / Parking:
Primary car park has room for about 10 cars, and is the closest to the playground (google maps link).
Secondary parking: A lot of people park along the road in. Where the road widens, there is space for parking along the right-hand shoulder of the road (google maps link). There’s parking for about 10 cars.
Public Transport:
There is no public transport to any of the entrances to Slieve Bawn. There is a local link bus from Strokestown to Scramogue - after which it's a 2km walk to the northerly trail head.
Trail difficulty: Easy
These routes use to mostly gravel access roads and small gravel trails.
Read about trail grading in Ireland here.
Trail quality: 2/5
This is a nicely developed recreation area around the wind farm. There are a lot of access roads.
Views: 3/5
A mostly forest-focused trail, with some views at the Trooperstown end. Lovely native woodland paths for the southerly section.
Buggy/Wheelchair friendly: Not all loops, but certain gravel paths are accessible for buggies. Unsure if wheelchair accessible.
When did I walk this route: December 2025
Dogs allowed: Yes
External Links:

This set of two small hills has become something of a local walk for me. Between these two summits, six different trails have been looped, offering a mix of distances and elevation.
Following the White Heritage Trail from the primary car park, the trail starts with the only steep section, bringing you up to the Holy Cross on the summit of the smaller hill. Erected during the winter of 1950-51, the cross pre-dates all of the forestry and access roads. Donkeys and horses were used to get all of the building materials up to the summit. Like many such crosses across the country, most of the work and funding all came from local people to the area.
This is one of three religious sites on the loop - the second being the mass rock, and the third being an old church ruin.
View fullsize





In the 1950’s, the Government Department of Lands began to buy parcels of land across the two summits for forestry development. While a lot of the forestry in the last few decades has been conifer plantation, there are some small sections of native planting, and each time I visit I come across another new layer of flora or fauna that I wasn’t expecting to meet.
From meeting a large Common Irish Frog on the path, to learning that ladybirds hibernate on gorse bushes, I appreciate these unexpected moments of nature connection.
View fullsize





One of the main reasons that I’ve been on more walks here recently, is because of Laika, the bundle of chaos that we call our dog. She loves a long walk, and she and I can easily walk 8 - 10km here and meet almost no one.
Crossing over to the second and higher summit, you can find a trig point hidden away on the summit. At only 262m, it’s probably one of the smaller hills that you will find a trig point on. However it feels a lot taller than it is, due to just how flat the surrounding boglands are.
View fullsize


Back on the 24th January 2025, Storm Eowyn hit Ireland, causing unprecedented damage across the island. It’s estimated that 24,000 hectares of forestry was damaged in Ireland - over four times that typical annual felling of Coillte (or national forestry company). That means that not only did all of the forestry teams suddenly have to try and process four times as much timber, but because of how it fell in the storm, so much of the wood was cross-loaded on other trees, making it an even slower job to process.
The devastation felt raw last spring - but with some time between now and that initial shock, I’m choosing to see it as an opportunity for goals like 30 for 2030 or the doubling of recreation sites to 500 to reach even further.




Sliabh Bawn is an interesting place for me to write about - because it’s a simple place. In the outdoors, I think there are a few different categories of necessary outdoor spaces. There are the “show-stoppers” that you travel for - offering unique experiences and showcasing the beauty of that area. And there are the places for the local community - the places close by and easily accessed, that give you time and space outside.
For me, Sliabh Bawn falls into the latter category. In the setting sun on a windy day, the views and colours from here can be spectacular, but it is not somewhere that has been developed for its incredible beauty. It's there to give people living in the surrounding area a place to call theirs.
View fullsize



December 2025: Storm damage from earlier this year (fallen trees) is still being cleared along the eastern slopes of Sliabh Bawn, impacting the White Trail. This looks to be cleared in the coming months, but at time of publication, it is recommended to detour along the pink (equine) trail for the eastern section.
The closest shop to the trail is in Strokestown (SuperValu)
Frank’s Bar is close to the trailhead
Andersons Thatch Pub for traditional music, and a place to park up if you’re in a camper
2025-12-08T10:00:00-05:00 from Yale E360
A study of thousands of children across the developing world found that those continually exposed to severe heat were more likely to see developmental delays.
2025-12-08T09:46:34+00:00 from alexwlchan
I don't trust platforms to preserve my memories, so I built my own scrapbook of social media.2025-12-08T03:17:29Z from Chris's Wiki :: blog
2025-12-08T03:16:41+00:00 from Simon Willison's Weblog
Niche Museums: The Museum of Jurassic Technology
I finally got to check off the museum that's been top of my want-to-go list since I first started documenting niche museums I've been to back in 2019.The Museum of Jurassic Technology opened in Culver City, Los Angeles in 1988 and has been leaving visitors confused as to what's real and what isn't for nearly forty years.
Tags: museums
Mon, 08 Dec 2025 00:00:00 +0000 from Blog on Jon Seager
This article was originally posted on the Ubuntu Discourse, and is reposted here. I welcome comments and further discussion in that thread.
Earlier this year, LWN featured an excellent article titled “Linux’s missing CRL infrastructure”. The article highlighted a number of key issues surrounding traditional Public Key Infrastructure (PKI), but critically noted how even the available measures are effectively ignored by the majority of system-level software on Linux.
One of the motivators for the discussion is that the Online Certificate Status Protocol (OCSP) will cease to be supported by Let’s Encrypt. The remaining alternative is to use Certificate Revocation Lists (CRLs), yet there is little or no support for managing (or even querying) these lists in most Linux system utilities.
To solve this, I’m happy to share that in partnership with rustls maintainers Dirkjan Ochtman and Joe Birr-Pixton, we’re starting the development of upki: a universal PKI tool. This project initially aims to close the revocation gap through the combination of a new system utility and eventual library support for common TLS/SSL libraries such as OpenSSL, GnuTLS and rustls.
Online Certificate Authorities responsible for issuing TLS certificates have long had mechanisms for revoking known bad certificates. What constitutes a known bad certificate varies, but generally it means a certificate was issued either in error, or by a malicious actor of some form. There have been two primary mechanisms for this revocation: Certificate Revocation Lists (CRLs) and the Online Certificate Status Protocol (OCSP).
In July 2024, Let’s Encrypt announced the deprecation of support for the Online Certificate Status Protocol (OCSP). This wasn’t entirely unexpected - the protocol has suffered from privacy defects which leak the browsing habits of users to Certificate Authorities. Various implementations have also suffered reliability issues that forced most implementers to adopt “soft-fail” policies, rendering the checks largely ineffective.
The deprecation of OCSP leaves us with CRLs. Both Windows and macOS rely on operating system components to centralise the fetching and parsing of CRLs, but Linux has traditionally delegated this responsibility to individual applications. This is done most effectively in browsers such as Mozilla Firefox, Google Chrome and Chromium, but this has been achieved with bespoke infrastructure.
However, Linux itself has fallen short by not providing consistent revocation checking infrastructure for the rest of userspace - tools such as curl, system package managers and language runtimes lack a unified mechanism to process this data.
The ideal solution to this problem, which is slowly becoming more prevalent, is to issue short-lived credentials with an expiration of 10 days or less, somewhat removing the need for complicated revocation infrastructure, but reducing certificate lifetimes is happening slowly and requires significant automation.
There are several key challenges with CRLs in practice - the size of the list has grown dramatically as the web has scaled, and one must collate CRLs from all relevant certificate authorities in order to be useful. CRLite was originally proposed by researchers at IEEE S&P and subsequently adopted in Mozilla Firefox. It offers a pragmatic solution to the problem of distributing large CRL datasets to client machines.
In a recent blog post, Mozilla outlined how their CRLite implementation meant that on average users “downloaded 300kB of revocation data per day, a 4MB snapshot every 45 days and a sequence of “delta-updates” in-between”, which amounts to CRLite being 1000x more bandwidth-efficient than daily CRL downloads.
At its core, CRLite is a data structure compressing the full set of web-PKI revocations into a compact, efficiently queryable form. You can find more information about CRLite’s design and implementation on Mozilla’s Security Blog.
Following our work on oxidizing Ubuntu, Dirkjan reached out to me with a proposal to introduce a system-level utility backed by CRLite to non-browser users.
upki will be an open source project, initially packaged for Ubuntu but available to all Linux distributions, and likely portable to other Unix-like operating systems. Written in Rust, upki supports three roles:
Server-side mirroring tool: responsible for downloading and mirroring the CRLite filters provided by Mozilla, enabling us to operate independent CDN infrastructure for CRLite users, and serving them to clients. This will insulate upki from changes in the Mozilla backend, and enable standing up an independent data source if required. The server-side tool will manifest as a service that periodically checks the Mozilla Firefox CRLite filters, downloads and validates the files, and serves them.
Client-side sync tool: run regularly by a systemd-timer, network-up events or similar, this tool ensures the contents of the CDN are reflected in the on-disk filter cache. This will be extremely low on bandwidth and CPU usage assuming everything is up to date.
Client-side query tool: a CLI interface for querying revocation data. This will be useful for monitoring and deployment workflows, as well as for users without a good C FFI.
The latter two roles are served by a single Rust binary that runs in different modes depending on how it is invoked. The server-side tool will be a separate binary, since its use will be much less widespread. Under the hood, all of this will be powered by Rust library crates that can be integrated in other projects via crates.io.
For the initial release, Canonical will stand up the backend infrastructure required to mirror and serve the CRLite data for upki users, though the backend will be configurable. This prevents unbounded load on Mozilla’s infrastructure and ensures long-term stability even if Firefox’s internal formats evolve.

So far we’ve covered the introduction of a new Rust binary (and crate) for supporting the fetching, serving and querying of CRL data, but that doesn’t provide much service to the existing ecosystem of Linux applications and libraries in the problem statement.
The upki project will also provide a shared object library for a stable ABI that allows C and C-FFI programs to make revocation queries, using the contents of the on-disk filter cache.
Once upki is released and available, work can begin on integrating existing crypto libraries such as OpenSSL, GNUtls and rustls. This will be performed through the shared object library by means of an optional callback mechanism these libraries can use to check the revocation lists before establishing a connection to a given server with a certificate.
While we’ve been discussing this project for a couple of months, ironing out the details of funding and design, work will soon begin on the initial implementation of upki.
Our aim is to make upki available as an opt-in preview for the release of Ubuntu 26.04 LTS, meaning we’ll need to complete the implementation of the server/client functionality, and bootstrap the mirroring/serving infrastructure at Canonical before April 2026.
In the following Ubuntu release cycle, the run up to Ubuntu 26.10, we’ll aim to ship the tool by default on Ubuntu systems, and begin work on integration with the likes of NSS, OpenSSL, GNUtls and rustls.
Linux has a clear gap in its handling of revocation data for PKIs. Over the coming months we’re hoping to address that gap by developing upki not just for Ubuntu, but for the entire ecosystem. Thanks to Mozilla’s work on CRLite, and the expertise of Dirkjan and Joe, we’re confident that we’ll deliver a resilient and efficient solution that should make a meaningful contribution to systems security across the web.
If you’d like to do more reading on the subject, I’d recommend the following:
Mon, 08 Dec 2025 00:00:00 +0000 from andy l jones
AI progress is steady. Human equivalence is sudden.2025-12-08T00:00:00Z from Anil Dash
2025-12-07T21:28:28+00:00 from Simon Willison's Weblog
Now I want to talk about how they're selling AI. The growth narrative of AI is that AI will disrupt labor markets. I use "disrupt" here in its most disreputable, tech bro sense.
The promise of AI – the promise AI companies make to investors – is that there will be AIs that can do your job, and when your boss fires you and replaces you with AI, he will keep half of your salary for himself, and give the other half to the AI company.
That's it.
That's the $13T growth story that MorganStanley is telling. It's why big investors and institutionals are giving AI companies hundreds of billions of dollars. And because they are piling in, normies are also getting sucked in, risking their retirement savings and their family's financial security.
— Cory Doctorow, The Reverse Centaur’s Guide to Criticizing AI
Tags: cory-doctorow, ai-ethics, ai
2025-12-07T21:28:17+00:00 from Simon Willison's Weblog
Thoughtful guidance from Bryan Cantrill, who evaluates applications of LLMs against Oxide's core values of responsibility, rigor, empathy, teamwork, and urgency.Via Lobste.rs
Tags: ai, generative-ai, llms, oxide, bryan-cantrill
2025-12-07T20:33:54+00:00 from Simon Willison's Weblog
What to try first?
Run Claude Code in a repo (whether you know it well or not) and ask a question about how something works. You'll see how it looks through the files to find the answer.
The next thing to try is a code change where you know exactly what you want but it's tedious to type. Describe it in detail and let Claude figure it out. If there is similar code that it should follow, tell it so. From there, you can build intuition about more complex changes that it might be good at. [...]
As conversation length grows, each message gets more expensive while Claude gets dumber. That's a bad trade! [...] Run
/reset(or just quit and restart) to start over from scratch. Tell Claude to summarize the conversation so far to give you something to paste into the next chat if you want to save some of the context.
— David Crespo, Oxide's internal tips on LLM use
Tags: coding-agents, ai-assisted-programming, oxide, claude-code, generative-ai, llms
Sun, 07 Dec 2025 12:00:00 -0800 from Julio Merino (jmmv.dev)
Putting FreeBSD’s “power to serve” motto to the test.
On Thanksgiving morning, I woke up to one of my web services being unavailable. All HTTP requests failed with a “503 Service unavailable” error. I logged into the console, saw a simplistic “Runtime version: Error” message, and was not able to diagnose the problem.
I did not spend a lot of time trying to figure the issue out and I didn’t even want to contact the support black hole. Because… there was something else hidden behind an innocent little yellow warning at the top of the dashboard:
Migrate your app to Flex Consumption as Linux Consumption will reach EOL on September 30 2028 and will no longer be supported.
I had known for a few weeks now, while trying to set up a new app, that all of my Azure Functions apps were on death row. The free plan I was using was going to be decommissioned and the alternatives I tried didn’t seem to support custom handlers written in Rust. I still had three years to deal with this, but hitting a showstopper error pushed me to take action.
All of my web services are now hosted by the FreeBSD server in my garage with just a few tweaks to their codebase. This is their migration story.
2025-12-07T12:00:00-08:00 from ongoing by Tim Bray
The GenAI bubble is going to pop. Everyone knows that. To me, the urgent and interesting questions are how widespread the damage will be and what the hangover will feel like. On that basis, I was going to post a link on Mastodon to Paul Krugman’s Talking With Paul Kedrosky. It’s great, but while I was reading it I thought “This is going to be Greek to people who haven’t been watching the bubble details.” So consider this a preface to the Krugman-Kedrosky piece. If you already know about the GPU-fragility and SPV-voodoo issues, just skip this and go read thatSun, 07 Dec 2025 05:28:32 +0000 from Shtetl-Optimized
The following is based on a talk that I gave (remotely) at the UK AI Safety Institute Alignment Workshop on October 29, and which I then procrastinated for more than a month in writing up. Enjoy! Thanks for having me! I’m a theoretical computer scientist. I’ve spent most of my career for ~25 years studying […]2025-12-07T04:12:06Z from Chris's Wiki :: blog
2025-12-06T21:37:19Z from Jonathan Dowland's Weblog
2025-12-06T18:30:56+00:00 from Simon Willison's Weblog
The Unexpected Effectiveness of One-Shot Decompilation with Claude
Chris Lewis decompiles N64 games. He wrote about this previously in Using Coding Agents to Decompile Nintendo 64 Games, describing his efforts to decompile Snowboard Kids 2 (released in 1999) using a "matching" process:The matching decompilation process involves analysing the MIPS assembly, inferring its behaviour, and writing C that, when compiled with the same toolchain and settings, reproduces the exact code: same registers, delay slots, and instruction order. [...]
A good match is more than just C code that compiles to the right bytes. It should look like something an N64-era developer would plausibly have written: simple, idiomatic C control flow and sensible data structures.
Chris was getting some useful results from coding agents earlier on, but this new post describes how a switching to a new processing Claude Opus 4.5 and Claude Code has massively accelerated the project - as demonstrated started by this chart on the decomp.dev page for his project:
Here's the prompt he was using.
The big productivity boost was unlocked by switching to use Claude Code in non-interactive mode and having it tackle the less complicated functions (aka the lowest hanging fruit) first. Here's the relevant code from the driving Bash script:
simplest_func=$(python3 tools/score_functions.py asm/nonmatchings/ 2>&1) # ... output=$(claude -p "decompile the function $simplest_func" 2>&1 | tee -a tools/vacuum.log)
score_functions.py uses some heuristics to decide which of the remaining un-matched functions look to be the least complex.
Via Hacker News
Tags: games, ai, prompt-engineering, generative-ai, llms, ai-assisted-programming, coding-agents, claude-code
2025-12-06T14:40:46+00:00 from Simon Willison's Weblog
If you work slowly, you will be more likely to stick with your slightly obsolete work. You know that professor who spent seven years preparing lecture notes twenty years ago? He is not going to throw them away and start again, as that would be a new seven-year project. So he will keep teaching using aging lecture notes until he retires and someone finally updates the course.
— Daniel Lemire, Why speed matters
Tags: productivity
2025-12-06T03:28:40Z from Chris's Wiki :: blog
Fri, 05 Dec 2025 21:37:04 +0000 from Pivot to AI
Last year, Apple started summarising news headlines with Apple Intelligence! But chatbots don’t summarise text — they shorten it. And mangle it. Apple was pumping out completely wrong headlines. The news sites got quite annoyed. The BBC officially complained. Apple switched the bad feature off a month later. But there’s no dumb idea, especially in […]Fri, 05 Dec 2025 21:26:17 +0000 from A Collection of Unmitigated Pedantry
This is the third part of our four-part series (I, II) discussing the debates surrounding ancient Greek hoplites and the formation in which they (mostly?) fought, the phalanx. Last week, we looked at how the equipment which defined the hoplite – hoplite (ὁπλίτης), after all, means ‘equipped man’) – and how it weighs in on … Continue reading Collections: Hoplite Wars, Part IIIa: An Archaic Phalanx?Fri, 05 Dec 2025 16:36:44 GMT from Ed Zitron's Where's Your Ed At
[Editor's Note: this piece previously said "Blackstone" instead of "Blackrock," which has now been fixed.]
I've been struggling to think about what to write this week, if only because I've written so much recently and because, if I'm
2025-12-05T06:56:00-05:00 from Yale E360
The growing number of satellites overhead may soon obscure photos taken by the Hubble Space Telescope and other orbiting observatories. New research finds that passing satellites could leave streaks on up to 96 percent of images.
2025-12-05T07:54:32+00:00 from alexwlchan
When you want to get the dimensions of a video file, you probably want the display aspect ratio. Using the dimensions of a stored frame may result in a stretched or squashed video.2025-12-05T06:03:29+00:00 from Simon Willison's Weblog
TIL: Subtests in pytest 9.0.0+
I spotted an interesting new feature in the release notes for pytest 9.0.0: subtests.I'm a big user of the pytest.mark.parametrize decorator - see Documentation unit tests from 2018 - so I thought it would be interesting to try out subtests and see if they're a useful alternative.
Short version: this parameterized test:
@pytest.mark.parametrize("setting", app.SETTINGS) def test_settings_are_documented(settings_headings, setting): assert setting.name in settings_headings
Becomes this using subtests instead:
def test_settings_are_documented(settings_headings, subtests): for setting in app.SETTINGS: with subtests.test(setting=setting.name): assert setting.name in settings_headings
Why is this better? Two reasons:
I had Claude Code port several tests to the new pattern. I like it.
Tags: python, testing, ai, pytest, til, generative-ai, llms, ai-assisted-programming, coding-agents, claude-code
2025-12-05T04:28:05+00:00 from Simon Willison's Weblog
Thoughts on Go vs. Rust vs. Zig
Thoughtful commentary on Go, Rust, and Zig by Sinclair Target. I haven't seen a single comparison that covers all three before and I learned a lot from reading this.One thing that I hadn't noticed before is that none of these three languages implement class-based OOP.
Via Hacker News
Tags: go, object-oriented-programming, programming-languages, rust, zig
2025-12-05T04:19:15Z from Chris's Wiki :: blog
Fri, 05 Dec 2025 00:00:00 +0000 from The Observation Deck
Note: This was originally published as a LinkedIn post on November 11, 2025.
I need to make a painful confession: somehow, LinkedIn has become an important social network to me. This isn’t necessarily due to LinkedIn’s sparkling competence, of course. To the contrary, LinkedIn is the Gerald Ford of social networks: the normal one that was left standing as the Richard Nixons and the Spiro Agnews of social media imploded around them. As with Gerald Ford, with LinkedIn we know that we’re getting something a bit clumsy and boring, but (as with post-Watergate America!), we’re also getting something that isn’t totally crooked — and that’s actually a bit of a relief.
But because I am finding I am spending more time here, we need to have some real talk: too many of you are using LLMs to generate content. Now, this isn’t entirely your fault: as if LLMs weren’t tempting enough, LinkedIn itself is cheerfully (insistently!) offering to help you "rewrite it with AI." It seems so excited to help you out, why not let it chip in and ease your own burden?
Because holy hell, the writing sucks. It’s not that it’s mediocre (though certainly that!), it’s that it is so stylistically grating, riddled with emojis and single-sentence paragraphs and "it’s not just… but also" constructions and (yes!) em-dashes that some of us use naturally — but most don’t (or shouldn’t).
When you use an LLM to author a post, you may think you are generating plausible writing, but you aren’t: to anyone who has seen even a modicum of LLM-generated content (a rapidly expanding demographic!), the LLM tells are impossible to ignore. Bluntly, your intellectual fly is open: lots of people notice — but no one is pointing it out. And the problem isn’t merely embarrassment: when you — person whose perspective I want to hear! — are obviously using an LLM to write posts for you, I don’t know what’s real and what is in fact generated fanfic. You definitely don’t sound like you, so… is the actual content real? I mean, maybe? But also maybe not. Regardless, I stop reading — and so do lots of others.
To be clear, I think LLMs are incredibly useful: they are helpful for brainstorming, invaluable for comprehending text, and they make for astonishingly good editors. (And, unlike most good editors, you can freely ignore their well-meaning suggestions without fear of igniting a civil war over the Oxford comma or whatever.) But LLMs are also lousy writers and (most importantly!) they are not you. At best, they will wrap your otherwise real content in constructs that cause people to skim or otherwise stop reading; at worst, they will cause people who see it for what it is to question your authenticity entirely.
So please, if not for the sanity of all of us than just to give your own message the credit it deserves: have some confidence in your own voice — and write your own content.
Fri, 05 Dec 2025 00:00:00 +0000 from The Observation Deck
Note: This was originally published as a LinkedIn post on November 11, 2025.
I need to make a painful confession: somehow, LinkedIn has become an important social network to me. This isn’t necessarily due to LinkedIn’s sparkling competence, of course. To the contrary, LinkedIn is the Gerald Ford of social networks: the normal one that was left standing as the Richard Nixons and the Spiro Agnews of social media imploded around them. As with Gerald Ford, with LinkedIn we know that we’re getting something a bit clumsy and boring, but (as with post-Watergate America!), we’re also getting something that isn’t totally crooked — and that’s actually a bit of a relief.
But because I am finding I am spending more time here, we need to have some real talk: too many of you are using LLMs to generate content. Now, this isn’t entirely your fault: as if LLMs weren’t tempting enough, LinkedIn itself is cheerfully (insistently!) offering to help you "rewrite it with AI." It seems so excited to help you out, why not let it chip in and ease your own burden?
Because holy hell, the writing sucks. It’s not that it’s mediocre (though certainly that!), it’s that it is so stylistically grating, riddled with emojis and single-sentence paragraphs and "it’s not just… but also" constructions and (yes!) em-dashes that some of us use naturally — but most don’t (or shouldn’t).
When you use an LLM to author a post, you may think you are generating plausible writing, but you aren’t: to anyone who has seen even a modicum of LLM-generated content (a rapidly expanding demographic!), the LLM tells are impossible to ignore. Bluntly, your intellectual fly is open: lots of people notice — but no one is pointing it out. And the problem isn’t merely embarrassment: when you — person whose perspective I want to hear! — are obviously using an LLM to write posts for you, I don’t know what’s real and what is in fact generated fanfic. You definitely don’t sound like you, so… is the actual content real? I mean, maybe? But also maybe not. Regardless, I stop reading — and so do lots of others.
To be clear, I think LLMs are incredibly useful: they are helpful for brainstorming, invaluable for comprehending text, and they make for astonishingly good editors. (And, unlike most good editors, you can freely ignore their well-meaning suggestions without fear of igniting a civil war over the Oxford comma or whatever.) But LLMs are also lousy writers and (most importantly!) they are not you. At best, they will wrap your otherwise real content in constructs that cause people to skim or otherwise stop reading; at worst, they will cause people who see it for what it is to question your authenticity entirely.
So please, if not for the sanity of all of us than just to give your own message the credit it deserves: have some confidence in your own voice — and write your own content.
Fri, 05 Dec 2025 00:00:00 +0000 from The Observation Deck
Note: This was originally published as a LinkedIn post on November 11, 2025.
I need to make a painful confession: somehow, LinkedIn has become an important social network to me. This isn’t necessarily due to LinkedIn’s sparkling competence, of course. To the contrary, LinkedIn is the Gerald Ford of social networks: the normal one that was left standing as the Richard Nixons and the Spiro Agnews of social media imploded around them. As with Gerald Ford, with LinkedIn we know that we’re getting something a bit clumsy and boring, but (as with post-Watergate America!), we’re also getting something that isn’t totally crooked — and that’s actually a bit of a relief.
But because I am finding I am spending more time here, we need to have some real talk: too many of you are using LLMs to generate content. Now, this isn’t entirely your fault: as if LLMs weren’t tempting enough, LinkedIn itself is cheerfully (insistently!) offering to help you "rewrite it with AI." It seems so excited to help you out, why not let it chip in and ease your own burden?
Because holy hell, the writing sucks. It’s not that it’s mediocre (though certainly that!), it’s that it is so stylistically grating, riddled with emojis and single-sentence paragraphs and "it’s not just… but also" constructions and (yes!) em-dashes that some of us use naturally — but most don’t (or shouldn’t).
When you use an LLM to author a post, you may think you are generating plausible writing, but you aren’t: to anyone who has seen even a modicum of LLM-generated content (a rapidly expanding demographic!), the LLM tells are impossible to ignore. Bluntly, your intellectual fly is open: lots of people notice — but no one is pointing it out. And the problem isn’t merely embarrassment: when you — person whose perspective I want to hear! — are obviously using an LLM to write posts for you, I don’t know what’s real and what is in fact generated fanfic. You definitely don’t sound like you, so… is the actual content real? I mean, maybe? But also maybe not. Regardless, I stop reading — and so do lots of others.
To be clear, I think LLMs are incredibly useful: they are helpful for brainstorming, invaluable for comprehending text, and they make for astonishingly good editors. (And, unlike most good editors, you can freely ignore their well-meaning suggestions without fear of igniting a civil war over the Oxford comma or whatever.) But LLMs are also lousy writers and (most importantly!) they are not you. At best, they will wrap your otherwise real content in constructs that cause people to skim or otherwise stop reading; at worst, they will cause people who see it for what it is to question your authenticity entirely.
So please, if not for the sanity of all of us than just to give your own message the credit it deserves: have some confidence in your own voice — and write your own content.
2025-12-05T00:00:00Z from Anil Dash
Thu, 04 Dec 2025 22:52:34 +0000 from Pivot to AI
Micron, which makes about a quarter of all the computer memory and flash in the world, is shutting down Crucial, its retail store. Crucial is closing in February next year — the AI hyperscalers are offering a ton of money to buy most of Micron’s output, for way more than consumers will pay. [press release, […]Thu, 04 Dec 2025 19:10:54 GMT from Matt Levine - Bloomberg Opinion Columnist
Continuation funds, Amazon drivers, a narrow bank, Trump accounts, crypto gambling and PDT puzzles.Fri, 05 Dec 2025 00:00:00 +1100 from Brendan Gregg's Blog







I've resigned from Intel and accepted a new opportunity. If you are an Intel employee, you might have seen my fairly long email that summarized what I did in my 3.5 years. Much of this is public:
It's still early days for AI flame graphs. Right now when I browse CPU performance case studies on the Internet, I'll often see a CPU flame graph as part of the analysis. We're a long way from that kind of adoption for GPUs (and it doesn't help that our open source version is Intel only), but I think as GPU code becomes more complex, with more layers, the need for AI flame graphs will keep increasing.
I also supported cloud computing, participating in 110 customer meetings, and created a company-wide strategy to win back the cloud with 33 specific recommendations, in collaboration with others across 6 organizations. It is some of my best work and features a visual map of interactions between all 19 relevant teams, described by Intel long-timers as the first time they have ever seen such a cross-company map. (This strategy, summarized in a slide deck, is internal only.)
I always wish I did more, in any job, but I'm glad to have contributed this much especially given the context: I overlapped with Intel's toughest 3 years in history, and I had a hiring freeze for my first 15 months.
My fond memories from Intel include meeting Linus at an Intel event who said "everyone is using fleme graphs these days" (Finnish accent), meeting Pat Gelsinger who knew about my work and introduced me to everyone at an exec all hands, surfing lessons at an Intel Australia and HP offsite (mp4), and meeting Harshad Sane (Intel cloud support engineer) who helped me when I was at Netflix and now has joined Netflix himself -- we've swapped ends of the meeting table. I also enjoyed meeting Intel's hardware fellows and senior fellows who were happy to help me understand processor internals. (Unrelated to Intel, but if you're a Who fan like me, I recently met some other people as well!)
My next few years at Intel would have focused on execution of those 33 recommendations, which Intel can continue to do in my absence. Most of my recommendations aren't easy, however, and require accepting change, ELT/CEO approval, and multiple quarters of investment. I won't be there to push them, but other employees can (my CloudTeams strategy is in the inbox of various ELT, and in a shared folder with all my presentations, code, and weekly status reports). This work will hopefully live on and keep making Intel stronger. Good luck.
{kind=link}
{kind=link}
{kind=link}
{kind=link}